
Browser Permissions

This will be the last post (for now) on the browser-side before we move into a discussion of the four specific APIs that make up advertising-focused elements of the Google Privacy Sandbox: Topics, Protected Audiences, Attribution Reporting, and Private Aggregation. The topic is browser permissions. Permissions come in two indirectly-related core specifications: the Permissions API specification and the Permissions Policy specification.
- The Permissions API Specification defines the mechanism by which users and/or the user agent can set permissions for which features in their browser web applications can access.
- The Permission Policy Specification is a server-side mechanism. It allows web site owners to set access rules for which browser features and functionalities (e.g. geolocation) third- parties embedded on a page (e.g., an iframe with an ad from www.thirdparty.com) can have access to. Permission Policy was previously known as the Feature Policy Specification. On the whole, that history is not relevant to this discussion. However there is one case, the Feature Policy JavaScript API, which is relevant since it has not been updated.
Most browser features are delivered through some type of API. Historically different APIs were inconsistent in handling their own permissions, For example, the Notifications API provided its own methods for requesting permissions and checking permission status, whereas the Geolocation API did not. The Permissions API evolved so that developers could have a consistent user experience for working with permissions.
There is also the fact that publishers and end users may have different requirements. While an end user or a user agent may allow access to geolocation information because they want a more customized experience, a publisher’s terms and conditions may say they will not access geolocation information for any reason. The publisher wants a way to ensure a mistake cannot happen and they somehow get geolocation information from that specific browser. How then does the browser rationalize these two important but conflicting priorities?
The Permissions API effectively aggregates all security restrictions for the context, including any requirement for an API to be used in a secured manner, Permissions Policy Specification restrictions from the publisher applied to the document, requirements for user interaction, and user prompts. So, for example, if an API is restricted by a server-side permissions policy, the returned permission would be denied and the user (client-side) would not be prompted for access. The two APIs are thus two sides of a single coin and work together to allow both users and top-level domain owners to set the permissions they wish in a non-conflicting manner.
Permissions API Specification
Web browser owners are continuously enhancing the functionalities of their browsers to provide better experiences, or a wider range of experiences, to their users. Users may not want to allow web sites they visit to have access to one or more of these features. The Permissions API Specification solves this problem. It defines the concept of a powerful feature. A powerful feature is a browser-side feature for which a user gives express permission for web sites they visit to use/access. Powerful features, except for a few notable exceptions, are also policy-controlled features which are also specified by website owners under the Permissions Policy Specification.
A permission for a powerful feature can have one of three states:
- Denied. The user, or their user agent on their behalf, has denied access to the feature. The caller cannot use it. Features which are denied by default include geolocation capabilities, camera access, or microphone access. Access to many of these “denied” features can be changed through prompts to the user (see Figure 1).
- Granted. The user, or the user agent on the user's behalf, has given express permission to use the feature. The caller can use the feature without having the user agent asking the user's permission. Examples of features granted by default are storage access where websites can store data locally, or script execution, which allows websites to execute JavaScript code.
- Prompt(ed). The user must provide express permission. The user agent will prompt the user for the express permission when a specific top-level domain asks to use it.
Figure 1 - Examples of Prompted Features

To be clear, even those features that are denied by default may actually have their default permissions state as “prompt”. This setting allows for a user to be prompted to provide express permission for that feature to be used. You can see this by clicking settings widget on the left-hand side of the browser address bar and clicking into site settings. This displays the current status of permissions for each powerful feature on that specific web site (Figure 2). This interface allows the user to manually set their preferences.
Figure 2 - Examples of Permission Settings in Chrome for a W3c.org Site

Developers can also use Chrome developer tools to examine permissions for any given frame on a specific page to ensure that permissions are handled the way the developer intends (Figure 3)
Figure 3 - Permissions as Shown in Chrome Developer Tools (under the applications tab)

Every permission has a lifetime, which is the duration for which a particular permission remains "granted" before it reverts back to its default state. A lifetime could be for a specific amount of time, until a particular top-level browsing context is destroyed, or it could be infinite. The exact lifetime is set when the user gives expression permission to use the feature. It can often be set by the user via a browser interface. Alternatively, it can also be hard-wired into the browser itself by the browser manufacturer.
All permissions are stored locally on the device in a permission store. For WIndows 11 this file is “Local State” and it can be found in the Chrome subdirectories:
C:\Users\<user_name>\AppData\Local\Google\Chrome\User Data
Each permission store entry is a key-value tuple consisting of permission descriptor, permission key, and state
Permissions Policies
Permissions Policies allows web developers to selectively block or delegate access to certain browser features when a user agent is viewing a page from their domain. We have already been exposed to Permissions Policies, in particular the Permissions Policy header, in the prior post on Client Hints Infrastructure. Client Hints, however, are only one aspect of browser behavior or features that can be controlled by permissions policies. The full standard list is shown in the resources section here.
This list, however, is always growing, as more specifications for more features are developed and W3C working groups design their specifications/technical approaches to meet the design goals for security and privacy as discussed in RFC 6973 - Privacy Considerations for Internet Protocols, which we discussed previously. The Google Privacy Sandbox is an excellent example of this, which is explored in a later section.
Permissions policies are implemented at two layers:
- The response header layer (as we saw for Client Hints)
- The embedded frame layer - mostly around iFrames and, in terms of the Sandbox technologies, Fenced Frames.
The header layer sets global policies for the specific user agent. The embedded frame layer is the more fine-grained. It inherits the settings from the response header layer, and its settings for the specific origin it (the iframe) controls supersede the permissions it inherits .
We’ll start by discussing the two mechanics for permission policies and then show how they interact. After that we will discuss the alternate Feature Policy Javascript implementation.
Permissions Syntax
Before we delve into the mechanics of permissions policies, there are some nomenclature definitions we need to understand. These are shown in Figure 4. You can come back to this reference as we discuss the mechanics until you are comfortable with the way policies are specified under Permissions Policies.
Figure 4 - Syntactic Elements of the Permissions Policy Specification
Response Header Syntax
The response header permission settings are the global default across any and all features and frames on a given page. They are the primary set of permissions used when there are no more specific policies put in place at the frame level.
The default structure of header permissions is relatively simple:
Permissions-Policy: <directive>=<allowlist>The directive is the feature which needs permissioning and the allowlist is the set of domains and subdomains to which permissions will be given. Let’s take some examples to show the range of options. It is not my intention to go exhaustively through the grammar and how it works. The main point is to show you generally how you set permissions in different ways.
Let’s use the top level domain of https://www.example .com. To block all access to the geolocation directive (feature) use the following:
Permissions-Policy: geolocation=()To allow access to a subset of origins, use the following:
Permissions-Policy: geolocation=(self "https://a.example.com" "https://b.example.com")In this example, we are allowing geolocation feature access to the top level domain (“self”, or https://www.example.com), and two of its subdomains, a.example.com and b.example.com. Note that the two full URLs are input in quotes with only spaces between.and the allowlist is enclosed in parentheses.
Permissions can be concatenated on a single line or broken out separately. The two examples below are equivalent:
Permissions-Policy: picture-in-picture=(), geolocation=(self "https://example.com"), camera=*;Is the same as:
Permissions-Policy: picture-in-picture=()
Permissions-Policy: geolocation=(self "https://example.com")
Permissions-Policy: camera=*The list of powerful features that can be controlled both by the header form and the embedded syntax form are shown here.
What happens if there is no Permissions Policy header on the page? In that case, every feature policy defaults to * - that is, all origins and subdomains have access to the feature.
Embedded Frame Syntax
Let’s say a publisher’s page, https://www.exaomple.com/home contains both a third-party iFrame embedded in a page for a payment widget as well as an iframe that contains an ad. The two iFrames are from different vendors, and the publisher wants to differentially give access to these two vendors to different powerful features. Only the payment widget should have access to the user’s identity credentials but the advertiser should not. At the same time, only the advertiser should have access to the geolocation feature as a way to know which ad to serve, but definitely for security reasons should never have access to the user’s identity credentials. How do they accomplish that?
This is where the embedded frame layer comes in. The embedded frame layer allows for more fine-grained and differential control of permission delegation than the header layer can provide. It allows the developer to set permissions at the frame level that may supersede those from the header layer.
The basic syntax of the embedded frame approach is as follows:
<iframe src="<origin>" allow="<directive> <allowlist>"></iframe>The src is the top level domain (or origin).. The allow="<directive> <allowlist>" sets the permission for the specific feature and identifies which third-party domains or origin subdomains have access.
One very important note to this approach is that once a permission is passed to a third-party, that third-party can pass the same permission on to other third-parties it does business with. The assumption is that if the third-party is trusted, then can be relied on to only share these permissions with parties that are also trusted.
So now let’s show how this would be implemented in our example.
Here is the header permission setting for the top-level domain on this page
Permissions-Policy: identity-credentials-get=(self)
Permissions-Policy: geolocation=(self)
Permissions-Policy: camera=*Now let’s show the embedded frame settings for the payments provider iFrame:
<iframe src="https://www.example.com" allow="identity-credentials 'self' https://www.payment_provider.com"></iframe>And here are the embedded frame settings for the ad provider’s iFrame:
<iframe src="https://www.example.com" allow="geolocation 'self' https://www.ad_provider.com"></iframe>
Figure 5 shows how these sets of permissions interact to give the correct accesses to the origin as well as the two third-parties.
Figure 5 - Resulting Permissions Policies for https://www.example.com/home

Again, the point here is not to drill deeply into the various combinations of syntactic patterns for either of these layers. The main concept to take away from this discussion is how the header layer and the embedded layer interact to provide fine-grained control of policies for the various parties that operate on any given webpage.
Alternate Feature Policy API Javascript-Based Mechanic
We previously mentioned that Privacy Policy evolved from another standard called Feature Policy. Feature Policy was subject to some generic design weaknesses of HTTP headers that were resolved as part of a more general update to header structures called Structured Fields. However, there was a Javascript-based approach to permissions under Feature Policy that has yet to be updated. So the alternate Javascript mechanic, the Feature Policy API, is the way permissions are handled using Javascript for Permissions Policy for now. A proposal to update the API into Permissions Policy exists, but not much has happened with it since early 2022. So it is not clear when or if these updates will be made.
The API consists of four endpoints that allow developers to to set or examine the allow condition for powerful features across either a document or an iFrame, depending on context, although the most common use is using the API to set permissions within the context of an iFrame. Figure 6 lists these four endpoints and describes what they do.
Figure 6 - Feature Policy API Endpoints
There are subtle differences between the implementation of these features at the document and iFrame level. For example, if the featurePolicy.allowsFeature(feature, origin) is called at the document level, the method tells you that it's possible for the feature to be allowed to that origin. The developer would still need to conduct an additional check for the allow attribute on the iframe element to determine if the feature is allowed for that element’s third-party origin. Those who wish to drill further into the API syntax and usage can see this MDN article on FeaturePolicy.
Permissions Policy and the Google Privacy Sandbox
Since this blog is all about the Privacy Sandbox, I would be remiss if I didn’t discuss exactly how Permissions Policy applies to the APIs specific to the Sandbox. There are two aspects to Permissions Policy to discuss in regards to the Privacy Sandbox:
- Permissions directives/features which apply to the various Privacy Sandbox APIs
- Embedded layer permissions in fenced frames
Permissions Features for Privacy Sandbox APIs
Figure 7 shows the features around Privacy Sandbox which can be controlled via the Permissions Policy Specification.
Figure 7 - Privacy Sandbox APIs Subject to Permissions Policy
Permissions Policy in Fenced Frames
Fenced Frames were discussed in a post at the beginning of Chapter 2. Fenced frames are an evolution of iFrames that provide more native privacy features and address other shortcomings of iFrames. The core design goal of fenced frames is to ensure that a user’s identity/information from the advertiser cannot be correlated or mixed with user information from the publisher’s site when an ad is served. Fenced frames have numerous restrictions relative to iFrames to ensure that such cross-site information sharing cannot occur.
These limitations, however, create a challenge for permissions policy. A set of permissions delegated from permissions headers to a fenced frame could potentially allow access to features that could be used as a communication channel between origins, thus opening the way for cross-site information sharing.
As a result, standard web features whose access is typically controlled via Permissions Policy (for example, camera or geolocation) are not available within fenced frames. The only features that can be enabled by a policy inside fenced frames are the specific features designed to be used inside fenced frames:
Protected Audience API
- attribution-reporting
- private-aggregation
- shared-storage
- Shared-storage-select-url
Shared Storage API
- attribution-reporting
- private-aggregation
- shared-storage
- shared-storage-select-url
Currently these permissions are always enabled inside fenced frames. In the future, which ones are enabled will be controllable using the <fencedframe> allow directive. Blocking privacy sandbox features in this manner will also block the fenced frame from loading — there will be no communication channel at all.
So we come to the end of Chapter 2 for now. I may decide to expand it later to include discussions of CORS, CORB and other security standards. But we’ll leave it here for now and begin the move into the server side elements of the Privacy Sandbox.

Client Hints Infrastructure

Introduction
In the last post I introduced the basics of browser and device fingerprinting and noted just how much information is available to any website or third-party tag embedded in a served page. The intention was to allow websites to optimize the user experience for the specific combination of device, operating system, browser, screen size, and more on a given viewer’s device. However, the amount of information available as a result of this open information sharing allowed for the identification of a specific individual user/user agent a majority of the time. This allowed for an alternative and very powerful form of cross-site tracking independent of cookies and other techniques.
The amount of information can be measured in terms of the concept of entropy that evolved from information theory, which you can think of as a meta-descriptor that tells you how many bits of information is needed and/or available to provide a unique identification. In this case, Eckersley in his seminal paper on fingerprinting estimated that the user agent alone contains 10 bits of information, or 210 (1,024 bits). That means that only 1 in 1,024 random browsers visiting a site are expected to share the user agent header. Add a few other features like screen resolution, timezone, and browser plugins (among others) and that number goes to 18.1 bits of information. That means only 1 in 286,777 other browsers will share its fingerprint.
That number may not seem large, but 286,777 unique visitors/day equates to several million unique visitors per month (for example if an average user visits twice a month that would equate to 4mm unique visitors). That means in one month on average 15 browsers would have the same fingerprint. Let’s take CNN, with 767.4 million viewers per month. If all those were unique viewers (which they aren’t), then that would mean on average only 2,675 browsers visiting the site would share a fingerprint with at least one other browser. That is few enough that fingerprinting becomes extremely useful in identifying individuals for marketing purposes, exactly what the Privacy Sandbox and other privacy-first technologies are trying to prevent.
In this post, we are first going to delve more deeply into the industry’s early response to limit the amount of information available for fingerprinting. Then we will explore Google’s specific responses: Client Hints Infrastructure and User Agent Client Hints. Even today, Safari or Firefox do not support Google's approach.. Edge does, as it is built on Chromium.
Early Responses to Browser Fingerprinting
It took almost 10 years for the OS and browser owners to deal with fingerprinting information in the user agent header. Mozilla was first mover in January, 2020 in Firefox 72. They then made similar changes to Mozilla on Android in Firefox 79 in July, 2020. Apple followed suit in September 2020 on both MacOs and iOS 14. The main changes fell into three categories:
- Freezing at the major browser version. Browser version no longer showed the minor version. So instead of 79.0.1 the user agent string was limited to 79.
- Hiding device-specific details. The UA string no longer provided detailed information about the specific Android version or device model.
- Hiding the minor OS version. Instead of providing the exact operating system version, the UA string in Safari 14 and later began reporting only broad version numbers or generalized information. Similarly, Firefox fixed the operating system version and did not report minor versions.
There are subtle differences between how Apple and Mozilla implemented these limitations. Those deltas are shown in Figure 1.
Figure 1 - Differences Between Mozilla’s and Apple’s Restrictions on the User Agent Header
Taking the example from the prior post here is the comparison of the before and after:
Before: Mozilla/5.0 (Linux; Android <span style={{color: '#016F01' }}>13; Pixel 7</span>) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.0.0 Mobile Safari/537.36After: Mozilla/5.0 (Linux; Android <span style={{color: '#016F01' }}>10; K</span>) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.0.0 Mobile Safari/537.36
The general structure of the user agent hasn’t changed. This avoided forcing the industry to rewrite their code to parse a user agent string (which would have been exceedingly painful). Instead the changes were subtle, as shown in Figure 2.
Figure 2: Diagram Showing Where Changes Fall in the Reduced User Agent String

The blue values in Figure 2 show those elements which will continue to be updated on all platforms (including Chrome). The green values indicate those elements which are to be unchanging on all platforms, or which in the case of Chrome will be controlled by User Agent Client Hints.
Google, obviously, chose not to implement these approaches and instead took a different tack. Beyond the privacy issues, Google also wanted to deal with the complexity of web servers had reading user agent headers in a passive mode. Many times, the server cannot reliably identify all static variables in the user agent header or infer dynamic user agent preferences. Additionally, publishers and their ad tech intermediaries have to query databases of user agent strings such as DeviceAtlas in real time to identify the device/OS/browser combination they are serving to. These database services are expensive, as is writing/maintaining the code. Google wanted to create a commonly-shared API interface that used standard metadata definitions of user agent elements to support active, standardized negotiations between browser and server to determine which elements could be shared. This would enhance privacy and lower costs even as it allowed sharing of high-entropy elements of the user agent header for optimal user experience.
Overview of the Google Client Hints Infrastructure
Google’s approach is titled Client Hints Infrastructure, with a specific user agent aspect called User Agent Client Hints. Client Hints Infrastructure provides the desired active interface while protecting privacy by requiring the high entropy descriptors to be shared only with appropriate permissions/opt-ins from the user agent. It also, by default, limits sharing of any high-entropy settings with third-parties on the page unless the top-level domain uses browser permissions (more in the next post) to specifically delegate that access to specific third-parties.
There are two ways to implement client hints infrastructure:
- An HTTP Header-Based Approach: Using HTTP request headers, which is available only for first-party contexts. There are two versions of this: request headers themselves and then through a metatag-based approach.
- A JavaScript API-based Approach: Using a JavaScript API, which can be used by an embedded script.
I will start with the header-based approach to introduce the basic concepts and then show how they translate into the Javascript API-based approach.
Universal Low Entropy Elements That Do Not Require Client Hints
Before I delve into Client Hints Infrastructure, it is important to understand the difference in how low-entropy and high-entropy client hints are handled. Low-entropy user agent elements don’t require Client Hints Infrastructure. They are sent by default to the server with all requests (see Figure 3 further down in this post). Those user agent elements are:
- Browser brand
- The browser’s significant major version
- Platform (operating system, e.g. Android, Windows, iOS, Linux)
- Indicator whether or not the client is a mobile device
These simple features do not provide enough information to be able to fingerprint a device.
The Client Hints Infrastructure Header Elements
There are only four header elements unique to the Client Hints Infrastructure API needed to implement its capabilities for accessing high-entropy hints. A fifth, the Permissions Policy header, is more broadly used and not unique to Client Hints.
- Accept-CH Header. When a server wants to access high-entropy client hints, it makes a call to the browser using the Accept-CH response header. It is a response header because the request header comes initially from the user agent calling the specific web page. The server then responds with the Accept-CH response header asking for information it needs (usually for optimizing the user experience). We’ll get into the actual mechanics shortly, but here is an example of what a simple Accept-CH header looks like:
Accept-CH: Viewport-Width, Width, Device-Memory
That is for non-user agent elements. The User Agent Client Hints specification specifically uses a slightly different nomenclature for any item that is part of the user agent, starting all requests with a Sec-CH-UA prefix:
Accept-CH: Sec-CH-UA-Model, Sec-CH-UA-Platform-Version, Sec-CH-UA-Arch
- Sec-CH-x or Sec-CH-UA-x Header. The Sec-CH-<x> and Sec-CH-UA-<x> headers are the structures by which specific high-entropy values are requested and returned from the user agent. The difference is that the former is for general client hints while the latter is for user-agent client hints specifically. The <x> is filled in with the specific property that is required. Here is an example for an item that is not part of the user agent header:
Accept-CH: Viewport-Width, Width
In a subsequent request, the client might include the following headers:
GET /image.jpg HTTP/1.1
Host: example.com
Sec-CH-Viewport-Width: 800
Sec-CH-Width: 600
Note that even though the server requested the features without the Sec-CH- prefix, the user agent returns the values using the Sec-CH-<x> header structure.
You can find the list of available client hints under the Resources section of theprivacysandbox.com here.
- Critical-CH Header. In general, the Accept-CH header only receives the allowed high-entropy hints back from the user agent on the second or any subsequent requests. If it is critical that every load, including the first, has the requested Client Hints, then the server can set a Critical-CH header to request those hints at all times. Here is an example of how the Critical-CH header is used:
HTTP/1.1 200 OK
Content-Type: text/html
Accept-CH: Device-Memory, DPR, Viewport-Width
Critical-CH: Device-Memory
- Permissions-Policy Header. As mentioned previously, client hints are only available to the top-level domain making the Accept-CH response. However, in many cases the publisher may want to share these settings with third-party vendors with JavaScript tags on the page that need access to these same settings, such as a iFrame that displays an ad and needs to know the screen resolution to correctly display the graphics. Here is an example of how the permissions policy header is used:
HTTP/2 200 OK
Content-Type: text/html
Accept-CH: Viewport-Width, Width
Permissions-Policy: ch-viewport-width=(self "https://cdn.example.com"), ch-width=(self "https://cdn.example.com")
Note that the permission is specific to one third-party site and each element has to be called out specifically. That way the top-level domain can share only those elements needed by the third-party and nothing more.
- Meta Tag Variant. Also mentioned previously is that there is a variant of the client hints infrastructure that allows developers to use a metatag to request specific client hints. That request has a form like that shown below:
<meta http-equiv="Accept-CH" content="Viewport-Width, Width" />
- Delegate-CH Header. The Delegate-CH header is used in the meta tag variant in place of the Permissions-Policy header. It appears as follows:
<meta http-equiv="Delegate-CH" content="sec-ch-ua-model; sec-ch-ua-platform; sec-ch-ua-platform-version">
Javascript-Based Approach
As mentioned earlier, only the top-level domain can use the header-based mechanic. Third-parties who have JavaScript tags embedded in a page must use the JavaScript-based version of Client Hints Infrastructure to request these values (the top-level domain can also use the JavaScript API variant). The Javascript-based mechanic uses a JavaScript navigator call - navigator.userAgentData - to access client hints. The default low-entropy elements can be accessed via the two properties: brand, mobile, and platform properties.
// Log the brand data
console.log(navigator.userAgentData.brands);
// output
[
{
brand: 'Chromium',
version: '93',
},
{
brand: 'Google Chrome',
version: '93',
},
{
brand: ' Not;A Brand',
version: '99',
},
];
// Log the mobile indicator
console.log(navigator.userAgentData.mobile);
// output
false;
// Log the platform value
console.log(navigator.userAgentData.platform);
// output
"macOS";
As always, don’t worry about what the code means. Just note the use of the navigator as well as the brand, mobile, and platform properties.
High entropy values are accessed through a getHighEntropyValues() call.
// Log the full user-agent data
navigator
.userAgentData.getHighEntropyValues(
["architecture", "model", "bitness", "platformVersion", "fullVersionList"])
.then(ua => { console.log(ua) });
Again, ignore the code per se. Just note the getHighEntropyValues() call and the way it calls five types of information. There are no Sec-UA-CH- or Sec-CH- elements. The desired information is called using the base names of the features.
The Critical-CH header is not relevant in this approach as there is no two-step round-trip as in the header-based version. However, if I am the top-level domain, it is not clear to me how the Permissions-Policy header is implemented in the JavaScript version. My guess is it isn’t and that permissions always have to be set using browser Permissions by the top-level domain in HTTP headers.
Accept-CH Cache and Accept-CH Frame
Before we delve into the mechanics and flows of Client Hints Infrastructure, there are two more critical concepts we need to introduce
The Accept-CH Cache is the location on the user’s hard drive where the permissions for what is allowed to be shared are stored. It is somewhat like an alternative cookie store in that sites can use each of the hints as a bit set on the client that will be communicated with every request. The cache allows for updates to what high-entropy hints can be shared. But because it is also like a cookie store, under the specification it is subject to similar policies as cookies. A user agent is required to clean out the Accept-CH cache whenever the user clears their cookies or the session cookies expire. There is also another header we have not covered, called the Clear-Site-Data header, which provides a mechanism to programmatically clear data stored by a website on the client-side. This can include:
- Cookies: Session and persistent cookies.
- Storage: Local storage, session storage, IndexedDB, and other client-side storage mechanisms.
- Cache: HTTP cache, including cached pages and resources. The Accept-CH cache is also subject to the policies set by this header.
The Accept-CH frame is a mechanism designed to optimize the delivery of Client Hints in HTTP/2 and HTTP/3 by leveraging the transport layer as a way to reduce the performance overhead of the multiple request-responses needed to call client hints. It is related to the Accept-CH HTTP header but operates at a different level to improve efficiency and reduce latency.
The transport layer is Layer 4 of the Open Systems Interconnection (OSI) model. OSI is a fundamental computing standard that provides for how computing devices communicate across networks that was released in 1984 (so 10 years before the Internet existed) and was fundamental for communication using old tech like dial-up modems. Explaining it is beyond the scope of this blog, but if you are interested there is a good introduction here.
We will discuss the Accept-CH frame at length in the next section, but for now just know that a "frame" refers to the smallest unit of communication in the transport layer. Frames are used to encapsulate different types of data, such as headers, data, and control information, and are transmitted over a single stream within a connection. Each frame type has a specific structure and purpose, allowing for efficient multiplexing of streams over a single connection.
The Basic Mechanics of Client Hints Infrastructure
The Basic Flows
Figure 3 shows how the client and server interface for client hints. As the diagram shows, there are five steps:
- First the TLS handshake between the browser and server occurs. (For those who really want to delve into how this works, the Chrome University videos are an excellent source to learn from).
- The Client sends a request header containing the default user agent elements that do not require Client Hints.
- The server responds with an Accept-CH header requesting the high-entropy values it needs to optimize the user experience.
- The browser now resends its original request but this time includes whatever of the requested values its permissions allow it to share.
- The server reads the specific values and then returns the page content to the user agent that is optimized for that specific set of values. At the same time it repeats the Accept-CH response header to indicate to the browser that it will want the same fields on the next request.
Figure 3- The Basic Mechanics of Client Hints Infrastructure
A Behind the Scenes Look
You can actually view this interaction for any website you visit in the Google Developer Console. Figure 4 shows what CNN uses. In this case it makes no Client Hints request and only receives back the default low-entropy settings (highlighted in yellow).
Figure 4 - CNN Client Hints Usage

Google, on the other hand, makes a large number of Clients Hints requests and gets them back (Figure 5).
Figure 5 - Google’s Client Hints Requests

While I am a big fan of the Sandbox and Google’s technology, I do find it interesting that the company that produces my browser (and thus sets the default of what can be shared) makes a call for so much information that its browser makes available to me. This could just be that Google knows the tech and thus implements it as it should be used. And perhaps this amount of information is not enough to fingerprint my browser uniquely (I’d have to do the detailed calculations and don’t have time right now). But it certainly causes me some concern as a consumer as to just how much Google is asking to know about my user agent.
Who Controls What Can Be Shared?
Which brings us to the question of who controls what gets shared from the user agent? Google sets the default, but there are settings in the browser that the user can set to prevent the sharing of certain client hints. I have not been able to find a discussion of how those work, so what I did to test it is shut off all tracking using the Data and Privacy settings in Chrome and then restarted my browser. I didn’t see anything change. And even with these settings Google was getting back a number of high-entropy signals (Figure 6):
Figure 6 - Google Client Hints Returned with All Tracking Settings in Chrome Turned Off

This is an area I wish Google would provide more documentation for so business people in the industry can understand better how much control the user has on what high-entropy client hints are shared.
Client Hint Infrastructure at the Transport Layer
As we noted in Figure 3, there is a five-step process for sharing client hints. The extra HTTP calls needed to support client hints can add significant overhead to page rendering. There is a workaround for this using something called Application Layer Protocol Negotiation. Application-Layer Protocol Negotiation (ALPN) is a Transport Layer Security (TLS) extension that allows the application layer to negotiate which protocol should be performed over a secure connection in a manner that avoids additional round trips and which is independent of the application-layer protocols. It is used to establish HTTP/2 connections without additional round trips. It can be used to implement a more efficient implementation of Client Hints Infrastructure, as shown in Figure 7. In this case, the Accept-CH response header is embedded in the TLS handshake, thus saving two steps in the process. Note that the Critical-CH header is no longer needed in this call, since there is no first step where a default set of values is sent to the server. TLS embeds the response header, not the initial request.
Figure 7 - The Transport Layer Mechanics of Client Hints
That’s a lot of information for one day, so I’ll stop here. Next up: Browser Permissions.
Browser Fingerprinting & Client Hints
We’re Back
So, I am finally back at it after several weeks away from writing. My absence has partly been due to work and family obligations. But mainly it is due to the major announcement Google made on July 22 about the fact it is deferring the deprecation of third-party advertising cookies from Chrome and instead implementing a consumer-choice mechanic.
Despite this change, Google said in multiple forums which I attended that the work on the Privacy Sandbox would continue unabated, but given such a major change I wanted to wait and let the dust settle before I jumped back into the fray. For the moment, things look to be stable without any further major shifts in the offing. So I will pick up where I left off.
Continuing the discussion in the prior post on headers brings us to a discussion of browser fingerprinting and some new browser header elements designed to reduce the ability of companies to fingerprint a user agent. These elements come under the heading of Client Hints Infrastructure or a subset known as User Agent Client Hints.
In order to talk about Client Hints, I first need to introduce the concept of fingerprinting - what it is and how it works. Then we’ll discuss guidance from the W3C on a framework to reduce the ability to fingerprint. This also involves providing an introduction to some basic concepts of differential privacy. At that point, we’ll then discuss the Client Hints mechanism and how it attempts to accomplish the goals laid out in W3C’s framework. I will discuss the first three items in this post. In the next post I will then explore how the technologists have worked to reduce the ability to fingerprint using multiple methods, including Client Hints Infrastructure and User Agent Client Hints.
What Is Fingerprinting
Fingerprinting is a set of techniques for identifying a user agent from characteristics of the browser or the device on which it runs. Some of these techniques are deterministic - for example by reading the user agent header - but many are derived using statistical learning. I am particularly familiar with fingerprinting as I built algorithms to do this work in 2012 in my first role in ad tech. At that time fingerprinting was fairly new. Peter Eckersley of the Electronic Frontier Foundation had published one of the earliest papers on a variant known as browser fingerprinting, “How Unique is Your Web Browser”, in 2010. In that paper, Eckersley found that five characteristics of browsers - browser plugins, system fonts, User-Agent string (UA), HTTP Accept-headers and screen dimension - allowed his team to identify a browser uniquely ~ 84% of the time. Note that this didn’t even take IP Address into account.
At the same time, Eckersley built a web-based tool called Panopticlick to test browser uniqueness. That tool still exists today at www.coveryourtracks.eff.org. A separate tool, called AmIUnique is also available. To give you a sense of how powerful browser fingerprinting is today, I put my Chrome browser (in which I am currently writing this) through AmIUnique as the report from AmIUnique is a bit easier to comprehend. Even though I have multiple layers of protection from online tracking, AmIUnique could uniquely identify my browser (a partial printout is shown Figure 1. The full analysis is shown as an appendix at the end of this article). In fact, it could use my browser protection elements, such as my do not track settings or my Ghostery plugin, as part of the fingerprint.,
Figure 1 - Partial Printout for My Browser from AmIUnique.org

Since Eckersley published his research, there has been a large body of further work that identifies and tests browser/device features to determine the most impactful. One especially robust study, which tracked 2,315 participants on a weekly basis for 3 years, examined over 300 browser and device features. However, most fingerprinting techniques rely on somewhere between 10 - 20 features. These are shown in the top half of the table in Figure 2.
Figure 2 - Main Categories of Browser and Device Features Used for Browser Fingerprinting
Mobile devices have other features that can be fingerprinted. These include the compass, accelerometer readouts, gyroscope readouts, and barometer readouts. I won’t cover these in any detail here as right now they are tertiary signals. Only 1-2 companies actually use these features in any way to fingerprint mobile devices. But I mention them here for completeness and to call out the fact that mobile fingerprinting uses slightly slightly different methods to accomplish device (vs. browser) fingerprinting.
Some of these features are easily available in the contents of web requests. An example is the user agent header. Using just these features for creating a fingerprint is called passive fingerprinting. However, most fingerprinting is active, which means it depends on JavaScript or other code running in the local user agent to observe additional characteristics.
There is a third form of fingerprinting - called cookie-like fingerprinting. Cookie-like fingerprinting involves techniques that circumvent the end user’s attempts to clear cookies. Evercookie, invented by Samy Kamkar in 2010, is an example of this. Evercookie is a JavaScript application programming interface (API) that identifies and reproduces intentionally deleted cookies on the clients' browser storage. Evercookie effectively hides duplicate copies of cookies and critical identifying information in storage locations on the browser - such as IndexedDB or in web history storage - so that when a user agent logs back in that information can be queried and retrieved, even if cookies have been deleted.
Why the W3C Cares About Fingerprinting
While I am focused on explaining Chrome’s approach to privacy in the Privacy Sandbox, browser fingerprinting is a broad issue that all browser manufacturer’s care about. The Worldwide Web Consortium (known by its shorthand name - the “W3C”), has published a document entitled “Mitigating Browser Fingerprinting in Web Specifications” that provides guidance to the various working groups developing web specifications. The point of the guidance is to ensure that each working group considers the fingerprinting “surface” its specification creates and works to minimize it.
The W3C leadership has been concerned about fingerprinting for quite some time. But it has become especially concerned about fingerprinting as cookies or other obvious forms of cross-site tracking are deprecated. This is because statistical methods of fingerprinting will become the de facto workaround as other methods are restricted. It doesn’t pay to close the front door when the back door is wide-open. So browser manufacturers, including Google, are enhancing the privacy features of their browsers to reduce the ability to fingerprint even as they are removing obvious cross-site tracking mechanisms like cookies.
Which brings us to the new Client Hints and User Agent Client Hints APIs as one technology to reduce the ability to fingerprint a browser. As part of this discussion, we are going to have to delve into the topic of entropy, which comes from information theory developed by Claud Shannon in 1948. This will serve as an introduction to a very mathematical topic that will become exceedingly critical later in our discussions about privacy budgets and the Attribution Reporting API. But for now a high-level summary will suffice.
What are Client Hints and User Client Hints APIs?
Client Hints Infrastructure is a specification that identifies a series of browser and device features and allows access to the information about them to be controlled by the user agent in a privacy-preserving manner. It uses several techniques to accomplish this:
- It allows each browser manufacturer to establish a “baseline” set of user agent features that can be easily available for any website to request for the purposes of serving content.
- It also identifies a set of “critical” features that a website can request in order to serve a web page correctly. These features are not easily available because they provide a large amount of information value - known as entropy - that can be used to fingerprint a user agent. Examples of this are the exact operating system version on the device and the physical device model.
- It provides for the ability of the browser manufacturer to give some control of these settings to the end user in a consumer-friendly fashion.
- It establishes a structured mechanic for content negotiation of these elements between the user agent and a web server.
- It allows for information sharing only between the user agent and the primary web server (the top-level domain). Third-parties whose content is on a web page cannot gain access to this information without express permission from the primary website.
- All accesses related to features subject to control by client hints must be deleted whenever the user deletes their cookies or the session ends.
There are several types of client hints, each of which are handled differently:
- UA client hints contain information about the user agent which might once have been found expected in the user-agent header. There is a separate specification for these features appropriately named the User Agent Client Hints Specification. The User Agent Client Hints Specification extends Client Hints to provide a way of exposing browser and platform information via User-Agent response and request headers, and a JavaScript API.
- Device client hints contain dynamic information about the configuration of the device on which the browser is running.
- Network client hints contain dynamic information about the browser's network connection.
- User Preference Media Features client hints contain information about the user agent's preferences as represented in CSS media features.
As we will discuss later, these hints are requested using a new header called an Accept-CH header, and each data element that is communicated in a request/response interaction is identified by a Sec-CH-UA (I assume the abbreviation is short for “secure client hints user agent”).
To get to that point, we need to go step-by-step through three topics. First we will take a walk down memory lane and review the history of browsers and the information they share. Next we will begin the discussion of entropy. Then we will go through and show some of the simple things that browser manufacturers did even before the Client Hints Specification to limit fingerprinting from the user agent header.
The History of the User Agent Header
User agent strings date back to the beginning of the Worldwide Web. Mosaic was the first truly widely-adopted browser. It was released in 1993 and it had a very simple user-agent string: NCSA_Mosaic/1.0, which consisted of the product name and its version number.
The original purpose of the user-agent string was to allow for analytics and debugging of issues within the browser implementation. At that time, the W3C recommended it be included in all http requests. Thus, openly including the user-agent header became the normal practice.
But as the web evolved, so did the user agent string. Browsers, the devices they ran on, and the operating systems they supported multiplied. Many major and minor versions of all three platforms (browser, device, OS) were in use at the same time. The combinations became extensive, and it became difficult for web developers to to have their code run correctly on the various combinations. Thus the user agent header added more information so that the web server would know what combination it was serving to and adapt the code to ensure a web page rendered properly on that combination of platforms. Before Client Hints and User Agent Client Hints, a user agent header looked something like this (I will show what this looks like after User Agent Client Hints in the next post):
Mozilla/5.0 (Linux; Android <span style={{color: '#016F01' }}>13; Pixel 7</span>) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.0.0 Mobile Safari/537.36
As you can see contains a lot of information passed in the clear and available to any website automatically with a call to the user agent. Mind you, it looks like a lot of gobbledygook, and how it became this way is a story in-and-of itself (for those interested, a very humorous take on the evolution can be found in Aaron Anderson's post "History of the browser user-agent string"). But the key point is that the user agent header evolved to create a better user experience. No one was really thinking about the privacy implications at the time. So no one thought twice about openly sharing that information.
But then came commercialization and advertising, which has consistently followed every new medium since the mid-1800s like bees to nectar. The unique part of this new medium was that its effectiveness could be measured in detail. Slowly but surely, advertisers and publishers got more sophisticated in their ability to know who they were advertising to in order to maximize their now understandable metrics like conversion rate and return on ad spend. They discovered that the very public information in the user-agent header, when combined with other signals, allowed them to easily identify a specific viewer.
These techniques, of which fingerprinting was only one, created significant privacy concerns among regulators and consumers. Consumers especially did not like that they kept seeing the same ads over-and-over on every site they visited, which occurred before good frequency capping tools existed. They felt stalked and surveilled, which ultimately resulted in privacy regulations like GDPR.
Equally important, the values of platform owners in the industry, especially Apple and Mozilla (which evolved from Mosaic) began to change. After all, their executives were consumers as well who experienced tracking. Plus they had to worry about regulators imposing increasingly restrictive regulations and penalties for failure to follow those regulations. Like any new behavior, at first this change was due to these mandates, but ultimately they became a reflex, and now almost a religion. And where one browser developer went, others followed due to the standards-based approach to web technologies that occurs through the W3C.
The annual W3C meetings are a place where the key technical owners of browsers (and in the case of Apple and Google, operating systems and devices) come together and share ideas. These are some of the brightest and most opinionated minds on the planet, and the discussions between them can be wide-ranging, brilliantly insightful, and intense. It was in these meetings and very specific working groups, that the privacy-first mantra first emerged and then became the undisputed correct approach. Apple started it with the creation of their ID for Advertising (IDFA), which was the first control with a mandatory opt-out default. Ultimately, their viewpoint came to be accepted across the board. Since then, a huge amount of work has been done across multiple working groups to ensure that the consumer has a privacy-first experience of the web. Much of the technology I discuss in theprivacysandbox.com emerged from this work.
And while cookie deprecation and visible user controls for opting out of cookies in Safari and Firefox were some of the earliest (and easiest) results of this work, masking information in the user-agent header wasn’t far behind because its very public sharing of identifying information was an obvious privacy vulnerability.
For this, the industry turned to something called information theory and its notion of entropy to solve the problem.
Introduction to Information Theory
Information Theory was a completely new field of endeavor created almost whole cloth by Claude Shannon while working at Bell Labs in 1948. Shannon had the insight that you could measure the amount of information in any communication. Today we take the concept of “signal-to-noise ratio” - an indication of the quantity of information in a transmission - for granted. But in 1948 the concept that you could measure information was unheard of.
The intuition behind quantifying information is that unlikely events, which are “surprising”, contain more information than high probability events which are not surprising. Rare events are more uncertain and thus require more information to represent them than common events. Alternately - and what is important for us in the privacy domain - is that rare events provide more information than common events.
Let’s take an example that impacts the user-agent header and which was actually implemented. This is the current breakdown of Windows OS versions in the market (Figure 3):
Figure 3 - Market Share of Windows Versions as of September, 2024 (Source: WIkipedia)
So if there are 250 million Windows PCs that access the Internet today and if the user agent says that I am dealing with a Windows 11 device, I know that I am dealing with a 1 in 84 million chance of identifying an individual user agent. Not great for targeting an ad. But if I see a machine running Windows XP, that gives me a 1 in 850,000 chance of identifying an individual user agent. That is a less likely event, and as such has much higher information content.
But now let’s look at the percentage of Windows 11 minor releases (figure 4):
Figure 4 - Windows 11 Versions (as a percentage of all Windows 11 Machines)
If I see a Windows machine with a 24H2 minor release, then my ability to identify an individual user agent is 1 in 1 million. That is much better than just knowing the major version, and contains more information, but still less than the “surprise” I get finding that there is still a Windows XP machine out there.
I will not go into the mathematical logic here, but it is important to understand for purposes of this discussion that the level of information decreases in a non-linear fashion (Figure 5).
Figure 5 - The Probability vs.Information Curve

What the chart shows is that the level of surprise drops more rapidly than linear as you move from low probability to high probability events. This means low probability events provide incrementally more information for “unit of increase in likelihood” than a linear curve. Or put another way, removing a low likelihood predictor from a predicting equation means that you can remove a lot more information. As you will see, this last statement is why we care so much about low probability vs. high probability events as we attempt to limit information loss via Client Hints Infrastructure.
Here is the second important point and it gets to a definition of what is called entropy. Note that the chart represents the tradeoff between probability and information for a single variable. But the user-agent contains seven critical pieces of information (variables) that allow for identification of a specific user agent. We need to know how much total information is contained in this complete set of features. We can then identify which features are high information versus low information and alter those with high information since this will have the most impact on identifiability of a specific user agent.
This is where the concept of entropy comes into play. Let’s say we have a specific user agent, X, we want to identify. The way we do that is to look at all the available elements in the user agent and the information they contain and determine the probability that that combination of element values (e.g. Android, Version 14.5, Chrome, Release 127.1.1.5, mobile device, manufacturer= Google, model = Pixel, model version 7) is an exact match to device X. In other words, if we put this into an equation where f(x) is the predictive mathematical function and p(y) represents “the probability that y has a certain value" then we can write this general equation as follows:
f(x) = p(OS) + p(OS version) + p(Browser) + p(Browser version) + p(device type) + p(manufacturer)+ p(model) + p(model version)
The units of f(x) are bits of information. Each p(x) contributes so many bits of information to the total. Also note that f(x) is a probability distribution. Its values will vary depending on the actual combinations of the values from the probability distributions of each p(x). The more bits of information, the higher the likelihood that we can say f(x) = X, that is we can identify the specific user agent.
The number of bits in f(x) is known as the Shannon entropy.
The Shannon entropy of a distribution is the expected amount of information in an event drawn from that distribution. It gives a lower bound on the number of bits needed on average to encode an outcome drawn from a distribution P.
The intuition for entropy is that it is the average number of bits required to represent or transmit an event (r.g. Identify a specific user agent) drawn from the probability distribution f(x) for the random variable X.
If a combination of p(x)’s yields an f(x) that has 30 bits of information for an accurate prediction of a single user agent’s identity, then our job as privacy experts is to alter or remove those p(x)’s so that as little information as possible is provided to make that identity. The fewer bits allowed in the actual calculation relative to the 30 bits, the lower our granularity in our ability to make a 1-to-1 match. For example if 30 bits = 1 device, 20 bits might only resolve to 10,000 devices, and 10 bits might only resolve to 2,350,000 devices (recall the curve is non-linear).
We will stop here for today as I just poured a huge number of bits of information (ok, I’m not above a bad pun) into your brain. We’ll pick up next on how privacy experts have gone about using these concepts to ensure the privacy of user agents.
Appendix: Full AmIUnique Printout for My Browser
Shown below is the full printout of the AmIUnique analysis shown partially in Figure 1. This should give you a good sense of just how much information is available to fingerprint your device.


Headers and Google Privacy Sandbox: An Overview
Introduction

We now move into the last two topics before we leave the browser side of the Privacy Sandbox behind: HTTP headers and browser permissions. We already did a quick review of HTTP headers in the post The Big Picture and Core Browser Elements. In this post we will delve a bit further, although not to a complete review of all standard HTTP headers, which represent a numerous coterie beyond the scope of this post and not really needed to understand the Sandbox. In the next post, we will talk about another unique element of the Google Privacy Sandbox: the User Agent Client Hints API. User Agent Client Hints is based on, and is a separate specification from, the more general Client Hints API.
User Agent Client Hints is collection of HTTP and user-agent features that enables privacy-preserving, proactive content negotiation between a browser and a server. They allow the browser to control what information can be shared and with what sites via an explicit cross-origin delegation mechanic. Once again, in case you have forgotten this by now (is that even possible?), one critical design feature of the Google Privacy Sandbox is to avoid cross-site reidentification of a user or user agent ID. User Agent Client Hints prevents various forms of browser fingerprinting which could be used to do such cross-site reidentification.
What are HTTP Headers
HTTP headers are an integral part of the HTTP protocol as it exists today. Headers are used to send essential information to and from the user agent to allow the server-side and browser to communicate effectively. Headers like the user agent header allow the server to send back the right configuration to render the web document correctly on a particular device/browser combination. Others describe the server from which the request came. Others allow or prevent cross-origin resource sharing. Others handle security to mitigate potential security risks like cross-site scripting attacks or clickjacking, among many other vulnerabilities. Those are just a few examples of the range of functions that headers provide in the back and forth between user agent and server-side. Most importantly from the perspective of the Sandbox, standards groups can define custom HTTP headers unique to their protocol that can use support applications they wish to deploy in the browser.
In many cases, custom HTTP headers like those used in the Google Privacy Sandbox are developed in conjunction with a parallel ability to perform some function using JavaScript. The reason for this is that JavaScript functions can slow web page response and rendering times. Many publishers do not like cluttering their pages with JavaScript tags. In fact, if you look at adTech history, one of the main reasons that Supply-Side Providers (SSPs) emerged early on was because publishers didn’t want to add JavaScript tags to their website from every advertiser or demand-side provider (DSP) they interacted with. SSPs required only one tag on the publisher’s website to handle any and all ad requests. Moreover, performance of the code itself becomes critical when you are dealing with an application requiring less than 100ms response times. Headers are often an alternate approach that provides higher performance.
As an example of the conversations that go on around this issue, here is an excerpt of July 3 meeting notes of the Protected Audiences API Working Group about creating HTTP headers to replace core JavaScript calls in the Protected Audiences API:
[Yao Xiao] Basically what happens today - the way tagging works - on the advertiser side we inject the iFrame and the server side returns a second response… But there are performance issues around iFrames and, equally, we have to make sure the tag supports the joinAdInterestGroup() API, which is a JavaScript API. But there are companies/users that don’t want to support a JavaScript API, they want a header-based solution instead. We have already done something like this for attribution reporting API and shared storage API. If we are going to move to the header-based approach above, we want to provide header-based support for all three endpoints - joinAdInterestGroup, leaveAdInterestGroup(),.....
[Isaac Foster] Ability to create interest groups via header - doing the light shell with refresh would be highly valued. Publishers are always hesitant to add JavaScript to their page.
How HTTP Headers are Structured
HTTP headers consist of two parts. The first part is the key. The second part is the information/value to be communicated. The key and the value in the key/value pair are separated by a colon. If there is more than one value to a key, the values are separated by a semicolon. Here is a simple example:
Content-Type: text/html; charset=UTF-8
Content-Type: multipart/form-data; boundary=sample
The sender includes these headers as part of the header section of the HTTP message.
Types of HTTP Headers
Figure 1 is a table showing the types of HTTP headers, what they are used for (generally), the restrictions on them, and examples of both standard headers and calls created to support the Google Privacy Sandbox. I am not going to drill further into the different header calls as, again, it isn’t necessary to understand the implications for the Sandbox. I will probably write a tech brief later to go through all headers by category so readers will have that as a resource. The main thing is to understand the example - how the Sandbox has created a variant of a type of header for a specific purpose of supporting its functionality.
Figure 1 - Types of Headers, Their Properties, and Examples

How Headers Work: A Generic Example
Given that we have talked a great deal about browser storage, it would be natural to ask “Where are headers stored in the browser?” In Figure 1, there is a mention of a limit on the length for a single header in Chrome of 4,096 bytes, and a total storage of 250Kb across all headers from all websites and web pages. That is not a great deal of space to provide in the browser, especially if like me you keep over 100 tabs open concurrently. While there's no theoretical limit on the number of headers you could fit within the total size limit (1,000 headers of 250 bytes each is technically possible), it's highly impractical. Most websites use a reasonable number of headers (typically less than 50). Exceeding that could lead to performance issues and compatibility problems.
So if that is the case, how do headers actually work? Are they stored, if so and for how long?
What I will do in this section is first talk about the generic mechanism for how to think about header processing and then I will give an example around a specific header.
Figure 2 shows the generic flow for a header request-response cycle. The small black-and-white boxes with stubs represent the RAM for the device to which they are attached.
Figure 2: A Generic Request/Response Header Flow

Step 1: When the user agent makes a call to a website, in this case www.example.com, the user agent builds the request headers in the client’s memory based on the URL, cookies, and other relevant information.
Step 2: The user agent sends the request headers along with the request data to the server.
Step 3: The server receives the request and stores it in memory for processing.
Step 4: The server prepares the response headers and the payload for the user agent.
Step 5: The server sends the response header along with the appropriate payload to the user agent.
Step 6: The server deletes the request and its response headers from the server memory
Step 7: Upon receiving the response, the user agent stores the response headers in client memory for processing.
Step 8: The user agent uses the response headers to understand the content type, status code, and other crucial details and the payload displayed or used by the web page as needed.
Step 9: Once the request-response cycle completes, the user agent discards the headers from memory to free up resources.
Whatever we do with headers in terms of taking in meta-information that is then used to process and return data to a client, in most cases storage is not an issue. Headers are not stored on the client but rather held in memory, and then only until processing of the headers is completed. At that point the header is discarded, making room for subsequent requests and responses.
This does not mean that data used in HTTP headers isn’t stored on either the user agent or the server side. The Set-Cookie header is a good example of this. The call below is a response header that causes the user agent to store a cookie in the Cookies SQLite file on the user agent’s local machine.
Set-Cookie: sessionId=abc123; Expires=Wed, 21 Oct 2024 07:28:00 GMT; Path=/
Headers like Cache-Control, Expires, and ETag are used to control caching behavior. These headers can lead to the storage of responses in the browser cache or intermediary caches.
- Cache-Control: This header can specify directives for caching mechanisms in both requests and responses. For example, Cache-Control: max-age=3600 indicates that the response can be cached for 3600 seconds.
Cache-Control: max-age=3600
- Expires: This header provides an absolute date/time after which the response is considered stale.
Expires: Wed, 21 Oct 2024 07:28:00 GMT
- ETag: This header is used for cache validation. It allows the server to identify if the cached version of a resource matches the current version.
ETag: "686897696a7c876b7e"
There are numerous other headers that cause data to be stored in cache or on the local client. These are just a few examples to give you a sense of the range of ways a header can use or store data locally before it is deleted from client or server memory.
How Headers Work: The Content-Type Header
Now let’s drill into a specific example of how headers are processed. We will use a very common response header - the content-type header, as an example (Figure 3). The Content-Type header specifies the original media type of a resource before content encoding. It ensures proper interpretation by the client and helps reduce the likelihood of a cross-site scripting attack.
Figure 3 - Request and Response for the Content-Type Header

The right hand side of Figure 3 shows a server with a resource - in this case a document - that is stored in multiple languages (English, French, Spanish), with multiple formats (html or pdf), with multiple potential encodings (gzip, br, compress). Encodings are compression algorithms used to reduce the amount of data that needs to be transferred over the network. As the diagram shows, there are three versions of the content: a URL for English (URL/en), for French (URL/fr), and a URL for Spanish (URL/sp).
On the left hand side of the diagram is the client that wants to retrieve the English version of the pdf for download. That information is sent in the request header to the server letting it know which variant of content-type it needs, the desired language of the content, and the types of content encoding that the user agent can process.
The server finds the correct content type in the correct language and sends it back using br content encoding along with a header that indicates what it has sent back (pdf in English, encoded using br) . Each line item in the response is a single response header, with the Content-Type header indicating it is returning a pdf. After completing the send, it deletes the original request and the response headers from memory.
When the browser receives that response along with the response header, it uses the information in the response header to use the correct decompression algorithm and then display the English version of the pdf in a browser-based pdf viewer. Once the page is displayed, the user agent deletes the response header.
User Agent Header Is In a Class of Its Own for Privacy
You may have noticed in the first row in Figure 1 there is a user agent header example. This is because the user agent header from a technical perspective is just another request header. That is its header type. But it is in its own type when it comes to privacy. This is because the user agent header has been used by data scientists, along with other information like IP Address, plug-ins, installed fonts, and screen resolution to statistically “fingerprint” a browser as another way of tracking. As a result, the user agent header is in a special class of its own and we will cover it in extensive detail in the next post.
Next Stop: Fingerprinting
The user agent header is not the only mechanism by which devices can be fingerprinted, So in the next post, we will start with an overview of fingerprinting and the various mechanics used. Then we will explore two new, interrelated standards that have evolved in the Privacy Sandbox to help reduce “the exposure surface” for fingerprinting. They are the Client Hints API and the User Agent Client Hints API.

Private State Tokens
Introduction

So we have finished with storage, per se. But there is one last topic to discuss that is “indirectly” related to storage - Private State Tokens. Private State Tokens are a new mechanism that is part of the Google Privacy Sandbox. They are designed to help prevent fraud and abuse on the web while preserving user privacy.
Private state tokens are a completely invisible, private way to validate that real users are visiting a web site. They allow one website or mobile app (a user agent) to validate in a privacy-compliant way that a particular user agent represents a real viewer, not a bot or other fraudulent entity. Once validated, the user agent stores the tokens so they can be used by the same or other websites or mobile applications to quickly validate the reality of the end user, rather than having to perform a completely new validation. This validation lasts as long as the lifetime of the tokens, which can be set by each website or application developer based on the particular needs of their business.
Private State tokens are intended to supplement, or replace, other validation mechanics such as a CAPTCHA or a request for PII. They are also designed to convey trust signals while ensuring that user reidentification cannot occur through issuance of the tokens themselves. As such, they are a critical part of the Privacy Sandbox.
The reason private state tokens are related indirectly to storage is that they actually have their own unique storage area on the user’s hard drive in Chrome. Moreover, they are not physically an integral part of the browser itself - not a browser ‘element’ per se. So I grouped them in the module on storage in the browser elements image. Similarly to CHIPS, however, private state tokens are their own privacy-preserving mechanic and a specific, unique topic that needs to be covered in their own right.
Private state tokens are part of a broader protocol called the Privacy Pass API. Apple has already implemented a similar technology in 2022 called Private Access Tokens, also based on Privacy Pass. I hope to discuss the Privacy Pass API, as well as the differences between Apple’s and Google’s implementation of the technology, in a future post. It is a bridge too far today given the length that this post will end up being.
Because the audience for www.theprivacysandbox.com is ad tech professionals, I am going to assume that you generally understand the concept of tokens. We discussed them a bit in the post on cookies. But if you are not familiar with tokens and how they are used in computing, here is a good introduction.
What Are Private State Tokens?
Tokens are a technical concept in computing which packages some information in a self-contained format that can be read by other computer programs. A cookie is one example of a type of token, but tokens can take numerous formats. Private state tokens are designed to enable trust in a user’s authenticity without allowing tracking. Their unique features include:
- They are encrypted. Private state tokens are encrypted in a way that makes them unique and unable to be identified as a specific user or user agent. All anyone can know is whether or not this particular requester is verified as a real person.
- They can be shared between websites without breaching user privacy. Private state tokens were designed to allow one website or app to validate that a user is “real” and place a series of private state tokens confirming that in the user’s browser or app. Later a second website can use that act of validation, contained in those tokens, to verify the user agent represents a real person without having to do their own validations and token issuance procedure.
- They are stored locally in the browser.
- They require one or more trusted issuers. Tokens are issued by trusted third parties that provide the tokens to websites. There can be as many of these as the market has room for. As of this writing there are five: hCaptcha, Polyset, Captchafox, Sec4u(authfy), Amazon, and Clearsale. A trusted issuer is likely to be a PKI certificate authority of some kind, although nothing in the specification requires that.
- They are redeemable. The act of checking that a user has a valid token is called a redemption. A token is sent from the browser to the token issuer who then verifies (redeems) the token and provides a confirmation of identity back to the website. This confirmation is in the form of a redemption record. This process occurs without the issuer being able to know anything about the identity of the user agent.
- Trusted issuers must be verified by the website requesting a redemption. The website that needs to verify the “realness” of a user must already have a relationship with a trusted issuer or must use what is known as a a key commitment service to validate the issuer. Otherwise, they have no way to trust the company redeeming the token.
- A bad acting issuer cannot identify a user. One very unique, but hugely important feature of private state tokens is that the issuer is unable to correlate its issuances on one site with redemptions on a different site. As a result, private state tokens are protected from a malicious issuer reidentifying a user and their behavior across websites.
Use Cases for Private State Tokens
With all the changes in browsers and the deprecation of third-party cookies, we are moving into a world where the browser is going to prevent websites and mobile apps from knowing or tracking any individual. An individual site may put its first-party cookies into a user agent or collect a device identifier where the consumer allows it on iOS or Android. But this is only between 20-30% of most website or mobile traffic. Tracking an individual identity across sites, especially where the user chooses to remain anonymous, will be very difficult, although given third-party identifiers like ID5 or UID2.0, not impossible.
That’s good from consumers’ perspective, and as a privacy professional I wholeheartedly agree. But perfect anonymity means fraudulent traffic is undetectable since I cannot distinguish a real person from a bot. So the Google Privacy Sandbox and similar technologies from Mozilla, Safari, Android and iOS, create a problem for identifying and measuring ad fraud. This will only get worse once Chrome deprecates third-party cookies.
Private state tokens solve a number of privacy issues inherent in today’s browser design, but they are especially useful for programmatic advertising. Their design solves many ad fraud challenges without requiring a stable, global, per-user identifier which would violate the cross-site tracking preventions inherent in the Sandbox. Some of the ad fraud use cases they can apply to are shown in Figure 1:
Figure 1 - Use Cases for Private State Tokens
What Data Does a Private State Token Contain
What data do these files contain and how do they work together to deliver information to allow the processing of private state tokens? Private state tokens contain mandatory fields and can also contain optional information (Figure 2).
Figure 2 - Types of Data Carried By Private State Tokens
This data is used in two core mechanics - token issuance and token redemption. There are other mechanics like versioning tokens to the latest standard and reissuance, among others, but we won’t delve into them in this post.
Issuing Private State Tokens
Figure 3 shows the mechanics of private state token issuance. You show use this and Figure 4 as references to follow the step-by-step text below, which admiittedly can be a bit dense and thus cause you to have to slow down to have to take it in.
Figure 3 - The Private State Token Issuance Process
- Step 1: The browser requests a document from a website.
- Step 2: The website responds by delivering the document. Along with the document, the website returns a token challenge in its response header:
WWW-Authenticate: PrivateAccessToken challenge=abc..., token-key=123..., issuer-key=456...
- Step 3: The browser checks for available tokens. If there are no tokens from any provider the browser requests user attestation from the website. Attestation is a process which determines if the user is real. Attestation could involve using a CAPTCHA, for example.
- Step 4: The website performs attestation and, if attestation is positive, sends that notification to the browser. Otherwise the user agent is considered invalid/fraudulent and the whole process stops right there. Kinda obvious.
- Step 5: If the website can attest to the reality of the user, it then needs to send a request for token issuance to an issuer. But to do that, it needs to trust that it is making the request from the issuer it expects and that the issuer is a valid/attested issuer of private state tokens.
The Private State Token API uses a mechanic to establish trust with the unknown issuer called key commitments. A key commitment is a cryptographic assurance provided by the issuer that includes the public keys and associated metadata used for token issuance and redemption. This ensures that all clients interacting with the issuer can verify the authenticity and integrity of the tokens.
Key commitments serve several purposes:- Transparency: Key commitments provide a mechanism for clients to fetch and verify the issuer's keys before engaging in token transactions.
- Consistency: Key commitments ensure that all clients receive the same set of keys, preventing malicious issuers from presenting different keys to different users.
- Trust: Key commitments allow clients to verify that the keys used by the issuer are legitimate and have not been tampered with.
- Key commitments depend on a key commitment service (KCS) to act as a trusted intermediary. Key commitment services verify that the key commitments clients see are identical. This ensures that the keys used by issuers are consistent and trustworthy.
Key commitments via a KCS work as follows:- Fetching Key Commitments. The client makes an anonymous GET request to the KCS endpoint, which has the form <KCS_endpoint_name>/ .well-known/privacy-pass with a message of type fetch-commitment.
struct {
opaque server_id<1..2^16-1> = server_id;
opaque commitment_id<1..2^8-1> = commitment_id;
}
- KCS Responds with Commitment List. The KCS responds with a list of key commitments, including the public key, expiry, supported methods (issuance, redemption, or both), and a signature.
struct {
opaque public_key<1..2^16-1>;
uint64 expiry;
uint8 supported_methods; # 3:Issue/Redeem, 2:Redeem, 1:Issue
opaque signature<1..2^16-1>;
} KeyCommitment;
- User Agent Verifies Key Commitments: The user agent verifies the signature of each key commitment to ensure its authenticity. It then stores the list of commitments for use in token issuance and redemption.
At this point, the user agent makes the following call to the issuer:
fetch('<issuer>/<issuance path>', {
privateToken: {
version: 1,
operation: 'token-request'
}
}).then(...);
This call kicks off the issuance request, of which there are two key preparation steps around nonces before the request is forwarded to the issuer
- Step 6: User Agent Generates Nonces. A nonce is a unique random numeric value that is often used in cryptographic applications. Nonces are used with private state tokens to ensure that each token is unique and immune to certain types of hacks, like replay attacks. Once the issuer has been validated and key commitments stored in the browser, the user agent generates a set of random nonces that are unique to each token request.
- Step 7. User Agent Blinds Nonces. The client blinds the nonces. Blinding is a cryptographic process that hides the original nonces while still allowing the server to sign them. These blinded nonces will be sent to the issuer as validation elements in the request. If the issuer sends back the same blind nonces in their response, then the user agent knows that whatever message it receives is from the issuer to whom is sent the original message. You can think of these nonces as one-time codes between two people transmitting messages that prevent a third-party from pretending to be either the sender and receiver of the messages.
- Step 8: User Agent Makes Token Issuance Request. Once the nonces are blinded, the browser forwards the token issuance request with the blind nonces included directly to the token issuer.
- Step 9: The issuer processes the token request and generates a token response, signs it with their private key, and sends it back to the browser. The response includes the previously blinded nonces
- Step 10: User Agent Unblinds the Signatures. The user agent then unwraps the issuer’s response using the appropriate public key and checks the blinded nonces. If they match what the user agent sent, then the response is valid and the user agent stores some number (n) of private state tokens in the browser private state token storage subdirectory.
Each user agent can store up to 500 tokens per top-level website and issuer combination. Also, each token has metadata informing which key the issuer used to issue it. That information can be used to decide whether or not to redeem a token during the redeemption process.
Redeeming Private State Tokens
Figure 4 shows the mechanics of private state token redemption (or failure to do so).
Figure 4 - The Private State Token Redemption Process
- Step 1: The browser requests a document from a website B, which is a different website from the one which initially generated the token issuance and storage in the browser.
- Step 2: The website responds by delivering the document. Along with the document, the website returns the same token challenge in its response header:
WWW-Authenticate: PrivateAccessToken challenge=abc..., token-key=123..., issuer-key=456...
- Step 3: The header request generates a document.hasPrivateToken(<issuer>) call that returns ‘Yes’ when it finds a token from an issuer. It does not have to be an issuer that website B has a relationship with.
- Step 4: There is a token from that issuer. Is there a redemption record for that token from that issuer on the device? If so, then the browser validates the user agent as “real” to the website and it moves forward with its ad request (Step 10)
- Step 5: Without a redemption record, the browser determines whether or not it has a direct relationship with the token issuer.
- Step 6: If the browser does not have a direct relationship with the issuer, it requests validation of the issuer through the Key Commitment Service using the same mechanic as during token issuance. Once validated, the key commitment service sends confirmation to the browser.
- Step 7: Given a valid token without a redemption record and a validated issuer, Website B sends a direct redemption request using the fetch endpoint.
fetch('<issuer>/<redemption path>', {
privateToken: {
version: 1,
operation: 'token-redemption',
refreshPolicy: 'refresh' // either 'refresh' or 'none', default is 'none'
}
}).then(...)
- Step 8: If the issuer can validate the token, it sends a redemption record back to the browser. if not, it rejects the request. The user agent then has a choice of options based on the website owner's preferences. It can choose to go through its own attestation and validation process (the most likely scenario), it can choose simply to treat the user agent as fraudulent, or it could take the risk of moving forward through its regular process without validation.
- Step 9: The browser confirms to Website B that the browser is a “real” viewer.
- Step 10: The website requests an ad from its programmatic partners.
- Step 11: A programmatic ad is delivered to Website B
- Step 12: Website B delivers the ad to the browser.
When a token is redeemed, the Redemption Record (RR) is stored on the device. This storage acts as a cache for future redemptions. There is a limit of two token redemptions every 48 hours, per device, page and issuer. New redemption calls will use cached RRs where possible, rather than causing a request to the issuer.
When I read of the restructions mentioned in the last paragraph, it made me wonder how any site could actually depend on validation. I mean, imagine a news site. I could come back to that multiple times a day. My browser could easily use up my redemption requests and therefore not be able to validate itself. The answer lies in the caching of the redemption request. Not only can user agents cache redemption records, they can also refresh them when necessary. This means that even if a user visits a site multiple times, the site can rely on cached redemption records without needing to redeem new tokens each time. This lowers the amount of validation requests the site needs to have validation via private state tokens remain effective. Should a particular user agent somehow hit its validation limit, the website can fallback to using other trust signals and mechanisms to complement token-based validation.
Another question you may ask is why is there a limit at all? While there are several privacy concerns that limiting the number of redemption requests in a time period helps ameliorate, a major one is preventing what is known as a token exhaustion attack. Token exhaustion attacks are a type of abuse where a malicious actor attempts to deplete the available tokens of a user agent or system. This can be done by repeatedly requesting tokens or by using tokens in a way that exhausts the supply, making them unavailable for legitimate use. One reason why an attacker might want to undertake a token exhaustion attack is for monetary gain. In some cases, tokens might have monetary value or be used in systems where they can be exchanged for goods or services, such as an ecommerce site. Exhausting tokens can disrupt these systems and potentially allow attackers to profit. Limiting the number of validation attempts helps reduce the likelihood of such attacks.
How Do Private State Tokens Differ from Third-Party Cookies?
While it may seem obvious, given that both third-party cookies and private state tokens are used to detect ad fraud it is worth calling out how private state tokens differ from cookies and why they are better for fraud detection in a world where consumer privacy is key. The table in Figure 5 provides a summary of those differences
Figure 5 - Differences Between Third-Party Cookies and Private State Tokens
Where are Private State Tokens Stored
Private state tokens are stored in the C:\Users\<username>\AppData\Local\Google\Chrome\User Data\TrustTokenKeyCommitments directory in Windows. The reason for this directory name is that private state tokens used to be called trust tokens. WIthin that directory there is at least one subdirectory (and there may be more, but I haven’t had enough usage yet to have more than one). Mine is named for a date 2024.6.20.1. I thought this might be a temporary subdirectory that held data only for one session, but looking back over many days the folder is still there. So this is a more permanent directory. The directory date seems to relate to the manifest version, which is 2024.6.20.1, as shown in the manifest.json file (Figure 6). But how they are related is unclear.
Figure 6 - Contents of manifest.json (with the version date highlighted)

Within this subdirectory are four files and a subdirectory:
- keys.json
- manifest.fingerprint
- manifest.json
- a license file.
- \_metadata: subdirectory
- verified_contents.json within the \_metadata subfolder.
One of the first things to notice is that three of the four files in the directory have dates of “12/31/1979”. That can’t be a real date. After all, the Internet did not even exist until 1990, when Tim Berners-Lee set up his server at CERN (which, BTW, I got to see first-hand on a trip to CERN to visit my son in 2015. Almost felt like I should genuflect to the thing.). Chrome 1.0 was not released until 2008. It turns out this is a known bug with certain files in Chrome that has not been fixed due to it being a low priority.
The manifest.json file is obviously a “meta” file containing the version of the manifest, its name, and version. This file, I am almost certain, is used by the browser to interpret which version of the Private State Token code is being used and whether it needs to be updated. Manifest files are usually used to indicate the version of a web application or PWA (Progressive Web App) and whether there are updates to the PWA that need to be fetched and applied. This use is defined in the Web Application Manifest specification, which, frankly, I was completely unaware of until I wrote this post. I believe that is what is happening in this case.
The license file appears to be the user license for private state token usage.
keys.json contains the references to both the issuers of tokens and the public encryption keys of the private-public key pair that these issuers use to encrypt tokens (Figure 7). As shown in the image, issuers may advertise multiple token-keys for the same token-type to support key rotation. In this case, Issuers indicate a preference for which token key to use based on the order of keys in the list, with preference given to keys earlier in the list. Remember from above that each token has metadata informing which key the issuer used to issue it. So at the time the token is called for a redemption request, the token will identify which of these keys was used and then send that with the redemption request to find the appropriate private key to use for decryption.
Note the "PrivateStateTokenV1VOPRF" element directly under the issuer name. This tells the browser which version of the API to use to process the token.
Figure 7 - Contents of keys.json file

The manifest.fingerprint file is not explicitly defined in the PST API specification, but it is commonly used in web applications to ensure the integrity and authenticity of the manifest file. This file typically contains a cryptographic hash of the manifest file, which can be used to verify that the manifest has not been tampered with. This is discussed extensively in the manifest specification I mentioned above. You can see an example of the code used to do the verification in the specification here.
Within the manifest subdirectory there is a file called verifiedcontents.json. This file contains metadata used by the PST application. My guess, given the contents, is that these files contain information needed by the PST API to determine which token to use for the API calls
Conclusion
This has been a really long post and perhaps "too detailed" for my target readers. It was difficult to write for a number of reasons, and I imagine it required a bit of persistence by the reader to work through it all. Frankly I’m not particularly happy with it, but it is the best I can do for now. So I am going to stop here. But at least now you understand what a Private State Token is and how its data is both stored and used in the browser, which was the original goal of this particular post. This really is the last element of browser-side storage we need to cover. It’s on to headers and permissions, and then we can start on the Protected Audiences API (finally!)

Web Storage After the Privacy Sandbox
This will be our last post on browser-side storage, thankfully. Thankfully because we can now move on to the core reason I began writing this blog in the first place - understanding the details of the Topics API, Protected Audiences API, and the Attribution Reporting API, along with their companion APIs like the Private Aggregation API. But before we get there, we have to cover three topics:
- Topics API Model (and Audience) Storage
- Interest Group Storage
- The Shared Storage API
The first two sections will be relatively brief as there isn’t that much to say. So, most of this post will focus on the Shared Storage API.
Interest Group Storage
As we have discussed before (here and here), interest groups are the audiences that are part of the Protected Audiences API specification. They are categorized as behavioral audiences to distinguish them from the Topics API audiences which are similar to, but not exactly the same as, contextual audiences. However, they can be more than behavioral. Interest Groups that can be uploaded to a specific browser or mobile device by a publisher using the Protected Audiences API, for example, can be of any type: demographic, psychographic, or taste-based, as well as behavioral.
Interest groups are loaded into any individual user agent using the joinAdInterestGroup endpoint. They are stored in a SQLite file called InterestGroups that can be found on your hard drive (if you are using Windows, the file can be found in C:\Users\arthu\AppData\Local\Google\Chrome\User Data\Default). It is possible to use a SQLite editor - as discussed here - to see the history of interest group activity on a given endpoint. Interest groups in a user agent are also displayed in Chrome developer tools (Figure 1):
Figure 1 - Example of How Interest Groups Display in Chrome Developer Tools

Topics API Model and Audience Storage
We haven’t talked much at all about Topics API yet - that actually begins in a few more posts. But at a high level: Topics API collects contextual information on how a specific user browses the Internet. It models that behavior locally in the browser on a weekly basis. The model takes as its inputs the content from the sites viewed by the user and categorizes that user agent into three audiences (out of approximately 600 in the audience taxonomy taken from the IAB). The models and the three audiences are both stored in the user agent.
There isn’t much to say about the storage used by the Topics API models and the audiences they create because for the most part anything to do with Topics API is happening ‘behind the scenes’ in the user agent and the mechanics are opaque to both developers and end-user. The end result of the algorithms, however - the actual audiences the browser is modeled into - are transparent to both the developer and the end-user. In fact, the end user can actually see what Topics API audiences they are part of. The end-user can also opt-out of being in Topics API audiences through a number of mechanisms already existing in Chrome. An example of one such mechanism is clearing all browsing history, which immediately prevents the user from being modeled into a group.
Here is an example of a call that a developer can make to the Topics API to retrieve the current audiences into which the user agent is categorized:
// document.browsingTopics() returns an array of up to three topic objects in random order.
const topics = await document.browsingTopics();
There is a more interesting tool available to developers that can be found by typing the following into the chrome address bar:
chrome://topics-internals
This provides a testing/debugging tool for developers that use Topics API. In the Classifier tab, you can type in the websites a group of viewers might look at. When you hit the “Classify” button, the browser displays the topics associated with the host that are stored in Chrome (Figure 2).
Figure 2 – Topics for Websites That Are Stored in the Browser by the Topics API

For how these topics have been associated with these websites, see the Topics API post.
Developers can also see Topics audiences in the developer console under the same Interest Groups tab as used for Protected Audiences interest groups. I am not clear on whether there is a clear indication of which audiences are from which API. Nor am I clear on why the Google Chrome folks decided this was the best way to handle things. Most likely it was a first approximation for MVP with more enhancements to follow as market feedback comes in.
Unless you are a browser developer, that’s about as much as about Topics API model and audience storage as you need know or worry about.
Shared Storage
We have talked a great deal about how the Privacy Sandbox uses dual-key partitioning to isolate data to prevent cross-site reidentification of a user’s profile and behaviors. The dual keys are:
- the site from which the content originates (the origin or context origin)
- the site on which the content is displayed (the top-level domain of the web page in which the context is displayed, also called in the specification the top frame site or the top-level traversable).
While this is great for privacy, it also creates problems for a variety of use cases that are essential for advertising. Let’s go through an example – implementing A/B testing of creatives - to help us understand the issues that partitioned storage creates. This example is taken from the Shared Storage API Explainer in the APIs core Github repository, but I am going to take it more slowly and use pictures to help explain what is going on.
A/B Testing Under Partitioned Storage
Let’s start in a case where we use dual-key partitioned storage. To be clear from prior posts, you can think of a single storage partition as being a storage bucket into which critical data, like first-party cookies or information about which ads were served to the browser, is stored. The storage bucket concept from the Storage API is an overarching mechanic which provides improved isolation for critical data. So even though cookies are stored in a SQLite file called Cookies, the implementation in Chrome for how they are stored in that file is subject to the improved isolation techniques implicit in the Storage API.
For any given user, I want them to see only one of two creatives, A or B, no matter what site they are on when they see the ad. In a world with partitioned storage, I cannot do that consistently since my activities on different sites can’t be cross-referenced.
Figure 3 shows the step-by-step as to why this won’t work with partitioned storage
Figure 3- Attempting A/B Testing with Partitioned Storage

Brand X has two different creatives, Creative A and Creative B, that it will have publishers display on any given site. It wants to do it in a way that 50% of viewers who see a Brand X ad always see either Creative A or Creative B.
Person A comes to a publisher site Publisher1 using their browser – in this case a third-party publisher like CNN or Raw Story.
Even with the Privacy Sandbox, Publisher1 can place a first-party cookie. As a result, Publisher1 can identify User A’s user agent(browser or mobile device) , can consistently serve them Creative A every time they visit their site and record that information in partitioned storage. This is true even if User A has opted out of anything but “essential cookies” (and note that there are different kinds of first-party cookies to which this opt-out does apply). This latter case is a bit “gray” and no doubt the privacy compliance folks may argue with me about this. But for purposes of this example, I am going to take a looser interpretation and say that showing the same ad to the same user agent on the same site using nothing but a first-party cookie isn’t a privacy violation.
With that latter assumption, this case is obvious and easy to implement.
The problem comes when Brand X now wants to find User A’s browser on Publisher2’s site. There is no third-party cookie to depend on, so Publisher2 puts its own first-party cookie in User A’s browser. It can decide to consistently show either Creative A or Creative B to User A’s browser and store that data in its (Publisher2’s) partitioned storage in the browser.
Now there are two problems. First, Publisher1’s first-party cookie has no tie-in to Publisher2’s first-party cookie, so there is no way to guarantee that User A is shown the same Brand X creative on both sites.
However, let’s say that just randomly User A does get served Creative A on both sites. Statistically this will happen 50% of the time and if we could connect the data from the two sites, we might still have enough data to make statistically valid reports about the performance of the two creatives for decision-making purposes. The problem is that in a partitioned storage world, when it comes time to do reporting, we can’t make that connection because the partitions prevent us from differentially combining data on User A. What we would need to do is look in both partitions, see where Creative A was served on both Publisher1 and Publisher2, and in those cases allow the data from both partitions to be aggregated in a reporting script runner for reporting with either the Attribution Reporting API or the Private Aggregation API. But we can’t do that. In the Privacy Sandbox, we can’t look inside the reporting script runner and see individual transactions. All we can do is aggregate ALL the data on impressions served on both sites, which means we cannot eliminate the impressions where User A was shown Creative B.
As a result, you cannot do A/B testing in a world without cookies but with partitioned storage.
A/B Testing with Shared Storage
Figure 4 shows the same use case when Shared Storage is available. We will only talk about the general concepts here. The next section will discuss the actual mechanics for how this works. The items highlighted in blue are what is different in the process between the two cases.
Figure 4 - Attempting A/B Testing with Shared Storage

In this case, when User A goes to Publisher1’s site, Publisher1 checks to see if User A has visited the site before when Brand X ads have been showing. If not, Publisher1 puts a “seed” in its storage area in a special shared storage worklet that indicates that User A was served Creative A on Publisher1 in an experiment identified as Experiment1. It knows to do this because there is a script that runs on Publisher1’s site when the ad request occurs indicating that the seed is from Brand X and saving it to Publisher1’s shared storage. The experiment number – Experiment1 - was provided by Brand X at the time the A/B test was designed The seed is tied to Experiment1, which in turn is associated with the URL where Creative A can be found.
When User A shows up at Publisher2, Publisher 2 also has Brand X’s script and the experiment number Experiment1. The script on Publisher2’s site makes a request to Brand X’s shared storage, via a worklet that tightly controls what data can be accessed and shared, using the Experiment1 ID as a match key. When the match key for Experiment1 is found, the seed is read and an opaque URL is provided by the browser that will deliver Creative A to User A’s browser. The entry reporting delivery of the creative is then stored in Publisher B’s shared storage.
When it comes time to report, the data from Publisher1 and Publisher2 are aggregated and are consistent in that both have shown Creative A to User A. Thus, any measurements for A/B testing will accurately reflect, as much as can be done with Privacy Sandbox aggregate reporting (which will be discussed later), the real performance of each unique creative.
Other Use Cases That Require Shared Storage
What are the most critical use cases where shared storage is considered necessary? They include:
- Cross-Site Reach Measurement
- Frequency and Recency Capping
- K+ Frequency Measurement
- Reporting Embedder Context
The Mechanics of Shared Storage
Now that we’ve explained why shared storage is essential for certain use cases, let’s explore how shared storage works. Let me note that up until now we have been focusing on browser elements more generally and have been setting up the tools/concepts you need to delve into the internals of the Privacy Sandbox. Moving forward from this post, we will be delving into technical discussions about the operations of the Privacy Sandbox itself. We won’t go to the code level except occasionally where it can exemplify some “higher level” conceptual point. We’ve done this before and hopefully you didn’t feel you needed to be a software developer in any way to understand the point I was making.
What is a Shared Storage Worklet
A shared storage worklet is a worklet with extra security restrictions on it to allow it to handle data shared between many sources in a privacy-preserving manner. These restrictions include:
- Shared storage worklets have limits on the APIs it can access relative to standard worklets.
- Shared storage worklets cannot directly access the DOM, cookies, or other web page data.
- Standard worklets can process data in its original format. Shared storage worklets can only process obfuscated data. The mechanic of that data obfuscation is internal to Chrome and is not available to the general public. .
- Standard worklets can communicate with the main webpage and other scripts using standard JavaScript mechanisms. Shared storage worklets, on the other hand, have limited external communication channels. They interact with webpages (like fenced frames) through predefined "output gates" that control what information can be shared based on specific purposes.
These differences are summarized in Table 1.
Table 1 – Differences Between Standard Worklets and Shared Storage Worklets
How is Data Retrieved from a Shared Storage Worklet
Data from a shared storage worklet can only be accessed (read) via output gates. An output gate is a specially-restricted environment by which data can be read. Basically think of them as a limited set of allowed use cases versus the kinds of data output allowed in a standard worklet. Today there are two output gates defined in the specification:
- Fenced Frame Output Gate. In this case, any output from the shared storage worklet must be in the form of a fenced frame. This requirement will not be enforced until at least 2026. In the meantime, output can occur to an iFrame.
- Private Aggregation Report Output Gate. This output gate specifically allows data to be read that is formatted according to the private aggregation API standards.
The following quote from the Shared Storage API specification describes these two output gates in a bit more detail
In particular, an embedder (authors note: an embedder is an origin that has written data to a fenced frame) can select a URL from a short list of URLs based on data in their shared storage and then display the result in a fenced frame. The embedder will not be able to know which URL was chosen except through specific mechanisms that will be better-mitigated in the longer term…
…An embedder is also able to send aggregatable reports through the Private Aggregation Service, which adds noise in order to achieve differential privacy, uses a time delay to send reports, imposes limits on the number of reports sent, and processes the reports into aggregate data so that individual privacy is protected.
How Do Shared Storage Worklets Relate to Fenced Frames?
As noted above, fenced frames are a specific output format that can be used by shared storage worklet. However, if you review the specification, it isn’t 100% clear that data will come into shared storage only from fenced frames. Fenced frames appear all over the code examples in the specification. For example (and, once again, don't worry abotu what the code means, just note the use of fenced frames):
function generateSeed() { ... }
await window.sharedStorage.worklet.addModule('experiment.js');
// Only write a cross-site seed to a.example's storage if there isn't one yet.
window.sharedStorage.set('seed', generateSeed(), { ignoreIfPresent: true });
let fencedFrameConfig = await window.sharedStorage.selectURL(
'select-url-for-experiment',
[
{url: "blob:https://a.example/123...", reportingMetadata: {"click": "https://report.example/1..."}},
{url: "blob:https://b.example/abc...", reportingMetadata: {"click": "https://report.example/a..."}},
{url: "blob:https://c.example/789..."}
],
{ data: { name: 'experimentA' } });
// Assumes that the fenced frame 'my-fenced-frame' has already been attached.document.getElementById('my-fenced-frame').config = fencedFrameConfig;
However, nothing in the specification states outright that shared storage worklets must only take in data from fenced frames.
Although there is no stated requirement, it is pretty clear why data for shared storage worklets must originate from, or be sent to, a fenced frame or some other privacy-preserving source like a private attribution report. Since the whole point of the Privacy Sandbox is to preserve privacy, it doesn’t do any good to use privacy-preserving storage for data that could be collected in a non-privacy preserving manner. Moreover, many of the use cases for shared storage are advertising driven, which means they center around ads delivered to a page. Once the Privacy Sandbox is fully implemented, all ads delivered to a site will be served in fenced frames. It thus makes sense that fenced frames are the assumed data source or one of two data receivers for shared storage.
Does that mean that fenced frames are the only privacy-preserving source that shared storage can use? That definitely is not clear, but it is certainly possible that shared storage worklets might be allowed to access specific, privacy-preserving data points from the main webpage through controlled APIs. However, directly accessing the entire webpage or user data is almost certainly not allowed.
How Is Data Stored in a Shared Storage Worklet
Data that moves into a shared storage worklet is obfuscated on entry. How that is done is a mystery that only the developers of shared storage worklets know. It probably involves privacy enhancing technologies (PETS) like homomorphic encryption or secure Multi-Party Computation (MPC).
Each shared storage worklet is associated with a database. Each browsing context has its own shared storage database , which provides methods to store, retrieve, delete, clear, and purge expired data. The data in the database is in the form of entries. Each entry has a unique key to identify it and associated data. In the prior example for A/B testing, the unique key would be a number and the data structure would include items like the time/date, the advertiser name (Brand X), the experiment number (Experiment1) and the creative shown (Creative A or B), and an entry expiration date/time .
Navigation Entropy Budget
The Google Privacy Sandbox has the notion of a privacy budget. This concept is not unique to Chrome. Privacy budgets are a form of differential privacy and are one of many new concepts from the world of Privacy Enhancing Technologies (PETs)
The basic notion of a privacy budget has to do with the information required to reconstruct a unique user profile. Every report generated from a browser releases a small quality of information known as entropy. At some point the cumulative entropy from all these reports could surpass the threshold needed to do reidentification. As a result, when cumulative entropy reaches a certain level, browsers are prevented from certain actions.
We will discuss privacy budgets in excruciating detail later (because they are really cool and have serious implications for introducing bias into reporting). But for now it is enough to note that data leaving a shared storage worklet generates some amount of entropy. According to the specification, the most leakage that can occur when a specific URL is chosen from within a shared storage worklet (for example, when calling a specific creative) is log 2(8) or 3 bits. This is because at most 8 obfuscated URLs can be stored to represent any one non-obfuscated URL and then be used when a call is made to deliver a URL out of the shared storage worklet via a fenced frame output gate.
It is possible if enough data exits shared storage in a specific browser, that browser may not be able to continue exporting data needed for specific use cases like A/B testing of ads. The Shared Storage API enforces a privacy budget per calling site per budget lifetime or epoch. The specification does not require a specific lifetime for which entropy collects before being reset to zero, but the explainer in the Github repository proposes a one-day lifetime in the Output Gates and Privacy section. When the shared storage worklet hits its budget, the specification states that the browser can only export the first entry in the list of eight URLs.
We’ll stop there for today. That should be more than enough information about the new forms of storage in the browser related to the Privacy Sandbox to carry forward into the core APIs. Just in the rereading, this is pretty dense material

Tech Talk: Navigables and Session Histories
In the last post, we talked about traversable navigables. I said I would delve a little deeper into these concepts to help you understand them at a more technically accurate level. You don’t need to read this post to understand browser storage at the level we need for the Privacy Sandbox. But I know many technical business people and product owners really like to understand the details. So if you are one of those people, this post is for you.
Documents and Session History Entries
We have talked a lot about session storage in past posts. But we have not really spoken in detail about what is stored there.
In order to do that, we must start with the concept of a document. I have used that term in past posts without defining it, because at a certain level everyone understands that a document is what they see on the web page. But that is not 100% technically accurate. For example, the Digital Video Ad Serving Template (VAST), an important standard for delivering video advertising into the browser (which we will discuss at length in regards to limitations of fenced frames and the Protected Audience API), contains the concept of a VAST document - the template - that contains information about the video to allow the publisher to present the video. You will hear developers over-and-over again in meetings (see this discussion) use the term “VAST document” instead of “VAST template”. While this is not the same conceptually as an HTML document, it is an extension of the concept to video. We will see this broader usage again in other contexts.
A document is a formal term in the HTML specification for a document object. It is represented by a concept you also have already been exposed to earlier - the Document Object Model or DOM. In essence, an HTML document is a text-based file that acts as the blueprint for a webpage. It uses elements and attributes (which I will not discuss here as now we are getting too far into the weeds) to define the structure and content, which the browser interprets using the DOM to display the webpage as you see it.
Three important items are set when the document is created:
- The document’s URL.
- The document’s origin.
- A document’s session history entry.
The browser fetches the given URL from the network and uses it to populate a new session history entry with the newly created document.
A document’s origin is the same origin we have discussed as the key used to partition storage. The origin is the top level domain (TLD) of the site/document. That is to say if you open www.example.com/sports_home, the origin is www.example.com and the key is a unique number tied to the TLD. Now there are subtleties I am not covering here - such as the fact that a document’s origin can differ from the current URL’s origin. But to keep things simple, we’ll stick to the basic notion that the origin is set when you open a document from a site that you are visiting for the first time in a session.
The document’s session history is stored, as you might expect, in the browser’s session storage. You can think of a session history entry as a snapshot of the web pages you have accessed during your current browsing session. They are essentially bookmarks that contain information that simplifies recreating a page should you open it again.
A session history is a formal code structure that contains ten items - including its URL, its document state, and its scroll position. The document state contains information to allow the browser to recreate the page quickly - say when you leave it and go back to it via the back button, or if the document is removed from the cache to avoid hitting storage limits (a familiar notion to you now if you’ve read prior posts). There is a cute term about cache here I just have to mention - the bfcache. The formal term is back-forward cache. This is a cache where browsers store the session history and the document state. But developer’s have renamed it “blazingly fast cache.” Leave it to developers to create cool names for what is otherwise a boring notion. Ya gotta love em.
There is also the notion of an active session history. This is the session history structure for the current document (web page) you are viewing.
Navigables
I could dig even deeper into documents and session histories but that’s all we need to know for now to move onto the next topic: navigables.
The technical definition of a navigable is an item that presents a document to the user via its active session history entry. You can think of it as a browser tab, but it isn’t actually a tab itself. It is a concept related to the browser’s history and navigation capabilities.
Figure 1 - The Relationship Between a Browser Tab, a Navigable, and the Navigation History File

Tabs are the visual representations of open webpages in your browser window. Navigables, on the other hand, are the underlying entries in your browsing history that enable you to navigate back and forth between those tabbed web pages (the ones you can revisit). It basically contains all the information needed to navigate to and from a particular web page. You can think of it like a bookmark. When you click the back or forward button in your browser, the browser uses navigables to find the previous webpage you visited in your session and display it. The navigable acts like a reference point for the browser to know where to take you back to.
Figure 2 - Elements of a Navigable and a Traversable Navigable

Navigables also have data structures consisting, in this case, of six items (Figure 2). They are
- A Navigable ID. This is a unique identifier assigned by the browser internally to each navigable. It's not directly exposed to developers and is used by the browser to manage navigables within your browsing history.
- A Parent Navigable. The parent element points to the parent navigable in the browsing history. This creates a hierarchical structure that reflects how you navigate between web pages.
Imagine you visit web page A, then B, and then C. The navigable for web page C would have web page B as its parent navigable, indicating you navigated to C from B. The navigable for webpage B might have webpage A as its parent, and the navigable for webpage A might have a parent of null (since it was the starting point).
- A Current Session History Entry.This element references the corresponding session history entry for the navigable. When multiple tabs are open, each tab has a separate current session history entry
- An Active Session History Entry. This element references the currently active session history entry. There can only be one active navigable/session history entry at a time. When multiple tabs are open, the active session history entry is for the webpage you're currently viewing.
- is closing Status. is status is a boolean flag indicating whether the webpage associated with the navigable is in the process of closing. It's initially set to false. When you close a tab or window, the browser might set this flag to true for the corresponding navigable to indicate that the webpage is being unloaded or closed. This can be used internally by the browser to manage resources associated with the closing webpage.
These elements within a navigable work together to provide the browser with the information it needs to manage your browsing history and navigation. The id uniquely identifies the navigable, the parent reflects navigation flow, the current session history entry points to the webpage details, the active session history entry indicates the current webpage is the focus, and the is closing flag helps manage resources upon webpage closure. Developers don't directly interact with these elements, but the browser uses them behind the scenes for efficient navigation and history management.
Traversable Navigables
A traversable navigable is a special type of navigable that has additional capabilities. It builds upon the foundation of a navigable, adding functionalities related to session history management and navigation control. If the navigable is a bookmark, the traversable navigable provides the information needed to move between bookmarks.
Having two concepts creates a clear separation between the basic representation of a visited webpage (navigable) and the more complex functionalities like session history management and navigation control (traversable navigable). This separation enables the browser to handle different types of browsing contexts (e.g., tabs, windows, frames) more efficiently. Not all navigables need full session history control, so traversable navigables can be used where necessary.
Let’s use an example to clarify the concepts. Imagine you open two tabs in your browser:
- Tab 1: Navigates to example.com (becomes a navigable). We will identify this as the main browser window.
- Tab 2: Navigates to subdomain.example.com (becomes another navigable).
Both tabs (navigables) are managed by the browser. They have unique IDs, can track their parent (likely the initial browser window), and point to their corresponding session history entries with details about the web pages.
However, only the main browser window might be a traversable navigable. This traversable navigable would then control the session history for both tabs (example.com and subdomain.example.com), allowing you to navigate back and forth between them using the browser's history buttons. It might also manage the bfcache for these pages.
The traversable navigable adds several elements to the elements contained in the navigable:
- A Current Session History Step. This element keeps track of the current position within the traversable navigable's session history. It's a number starting from 0, and it indicates the specific session history entry that is considered the "current" page within the context of the traversable navigable.
- Session History Entries. This list stores all the session history entries associated with the traversable navigable. It essentially acts as a log of all the webpages you've visited within the context managed by that traversable navigable. This list is crucial for the traversable navigable to manage the session history for itself and potentially its descendants (other navigables within its control, see below). The browser uses this list to provide functionalities like the back/forward buttons and potentially the bfcache.
- A Session History Traversal Queue. This is a standard queue data structure. The browser uses it to manage the order of navigation steps (back/forward) within the session history. Imagine a line of steps, where you add new steps (forward navigation) at the back and remove steps (backward navigation) from the front.
- A Running Nested Apply History Step. A bit too deep for us, but mentioned for technical accuracy and completeness. This flag helps the browser avoid conflicts or unexpected behavior when multiple navigation actions happen within a nested browsing context (frames or iframes).
- A System Visibility State. This is a boolean flag which is set to either hidden or visible. This element tracks whether the browser window or tab associated with the traversable navigable is currently visible or hidden. A hidden state occurs when you minimize the window or switch to another tab. The visibility state can be used by the browser to optimize resource management or handle situations where a webpage is not actively being viewed. For instance, the browser might pause timers or animations on a hidden webpage to conserve resources.
Child Navigables and Navigable Containers
Traversable navigables, as objects, can live in a hierarchy. Four concepts: top-level navigables, child navigables, navigable containers, and content navigables all work together to represent the hierarchical structure of your browsing history and the relationships between web pages within that history. The relationships between these concepts are shown in Figure 3.
Figure 3 - The Relationship Hierarchy Between Traversal Navigable Types

A top-level traversable is the top level of the hierarchy. All traversable navigables are top-level traversables because they are the root element in the hierarchy.
Child navigables are traversable navigables that are nested or embedded within a top-level navigable or another child navigable. This creates a hierarchical parent-child relationship. An iFrame within a web page could be represented by a child navigable that inherits its session history management from its parent (the top-level navigable or another child navigable). They can also have their own limited navigation control within the frame/iframe.
Content navigables represent the actual web pages themselves within this hierarchy. They don't have session history management capabilities - and thus are not “pure” navigables by the definition of the object - but are essential elements within the structure.
Navigable containers are a type of navigable that can group other navigables (often child navigables). They might be used for specific browsing contexts where managing a group of related web pages together is beneficial.
Well I expect that’s enough technical detail to hold you for some time. So I’ll stop here. Again, it was probably too much detail for the average reader, but it was fun for me to write about and I do not doubt that more than a few folks will enjoy this detour into browser mechanics.
NEXT UP: Browser Storage After The Sandbox (FINALLY!)

The Storage Specification

Introduction
We have talked about partitioning as it relates to storage extensively two posts back. We discussed that partitioning as a concept is almost as old as browsers themselves, and that many of the current storage elements in a browser are partitioned by origin. We also noted that partitioning in the context of the Google Privacy Sandbox refers to the addition of other partition keys - most commonly the current URL, to create a partitioning tuple of <”URL”, “origin”> so that embedded elements like iFrames cannot perform cross-site reidentification of a user agent.
The problem is that partitioning exists in the larger context of a broad, on-going evolution of client-side browser storage. This evolution is being driven by the many enhancements of existing storage-related elements/APIs like IndexDB, new storage types like Shared Storage, as well as the large amounts of additional information to be stored in browsers that results from moving programmatic auctions from ad servers to the client. Moreover, the need to partition all types of browser storage for the Privacy Sandbox allows for a rearchitecting of how storage is managed that ensures a more secure and private platform overall.
The response is contained in an evolution of a browser-side storage standard called, oddly enough, the Storage Standard. We mentioned this standard and its API at the end of the first post on browser storage. It extends the basic storage concept contained in Section 12 of the official HTML Standard, which itself builds on the IETF cookie standard by adding local storage and session storage, to cover all other types of storage.
While the standard is somewhat hard to imbibe, the concepts it is built on which we need to understand are relatively straightforward. They are shown in Figure 1.
Figure 1 - The Storage Hierarchy Underlying the Storage Standard

Basically, the new storage architecture is a hierarchy of storage concepts, each of which is finer grained and is a child of the prior element in the hierarchy. You can also think of this as the storage partitioning architecture now being implemented in Chrome to support the Google Privacy Sandbox, although its design was not specifically tied to the Sandbox but rather a much wider range of use cases. The broad reasons for evolving this new standard are that it provides:
- A standardized, widely-supported way to organize key-value pairs using localStorage and sessionStorage with improved control.
- A clear separation between data that persists until cleared (localStorage) and data that persists only until the browser window/tab is closed (sessionStorage).
- A better ability to manage these storage types at a much finer-grained level.
Let’s dive into the architecture and see how it works.
Level 1: Browser Data and Session Navigation History
Let’s start right at the top and work our way down. These elements at the top (first level) of the diagram are data about the browser and the user’s session browsing history:
- User Agent. The client browser. This browser has a user agent header that describes it and data that will be held in some storage type locally in the browser. This is the “local” data that flows into the next level of the storage architecture.
- Traversable Navigable. This is a big set of words for what the average web user thinks of as a browser tab containing a web page. It’s a bit more complex than that, as it really is the open browser page and the history of any prior pages that were opened in that tab and the order in which they were opened. In fact it is a lot more complex than even that description, and to a certain extent I am at a loss as to how deep to delve as there are some basic concepts here, like navigables, which you probably should know. But at the risk of the software developers telling me “that isn’t technically accurate”, I am going to stick to a simple discussion here and then delve a bit more deeply into these concepts in the next post. For those who wish to get the complete background, jump to the next post and then navigate (Ah hah! Maybe related to a navigable? Ya think?) back here.
Think of traversable navigables as a list of entries within your browser's browsing history that represent web pages you can navigate back to using the back and forward buttons. They act like a bookmark manager specifically designed for efficient back/forward navigation. The data for each traversable navigable (i.e., a list of pages visited) is stored in a particular kind of cache called the backwards-forwards cache or bfcache and the entire browsing history for that session is deleted when the tab or browser is closed. This is the “session” data indicated in Figure 1 that flows to the next level.
As previously discussed, session data can run across multiple tabs from the same website and expires at the end of a session. So if multiple tabs from the same site are open, the session data remains in session storage until all tabs from the site are closed. That is why you will often see a second term - top-level traversable set. It indicates the multiple tabs open to a specific website session.
So what data is defined as part of this element. When a specific traversable navigable is created, the following data is used to instantiate it:
- A document. All the content for the web page (e.g. an HTML file)
- An origin. See the definition of origin if you need a refresher. Basically, this is the top-level domain of the document.
- An Initiator Origin. An initiator origin is the top-level domain of the web page that initiated the request that loaded the current page. This concept applies when an action on one webpage triggers something on another webpage. This is not a case of going to another page within the same top-level domain (origin). That is navigating within the same origin, so the origin and initiator origin are the same. An initiator origin has to be a different origin than that for the page that loads
- A Navigable Target Name. A specific section within a webpage's history. When a user navigates through a webpage using the back and forward buttons, the browser keeps track of their browsing history. The navigable target name helps identify a particular section (e.g., a heading or a specific part of the content) within that history entry. It is used for efficient back and forward navigation. It also helps avoid full page reloads, so it has performance benefits as well.
- An About Base URL. This is the URL of the pages about: schema page. Trying to explain this in detail requires its own post. Moreover, I have searched the web and cannot for the life of me figure out what function this item plays in the function of a traversable.
The data the transversable navigable holds over time grows as the user traverses through web pages. We discuss that further here. For now it is enough to know that this data will flow into the first level of the storage architecture.
Level 2: Storage Sheds
A storage shed is the highest level of the storage architecture in the browser (more exactly in a user agent, but we’ll let the term “browser” be a stand-in for now). There are two kinds of storage sheds:
- The first type of storage shed holds a set of storage keys, each of which is assigned to a particular origin. The key is the origin’s tuple. Think of this storage shed as a self-service storage facility that holds all the browser’s locally-stored data (local storage). Each unit in the shed is a secured locker for one top-level domain to store all its information. The number of the unit is its key. This number also happens to be the code to its lock.
- The second storage shed occurs at the traversable navigable (tab/session) level. It also is a storage facility, with each unit being an origin key which provides a secure storage area for an origin’s session data. This type of storage shed is specifically designed for data related to your browsing history. It might store information like the navigable target name (discussed earlier) to help you jump to specific sections within a web page when navigating back and forth.
Thus right at the top of the architecture we now see that local storage and session storage have each been partitioned and parititioned separately into their own isolated storage areas. They are partitioned by a single key - the origin.
Level 3: Storage Shelves
A storage shelf is the private storage unit for each origin/TLD within the storage facility, to continue the analogy. It ties to its key that is stored in the storage shed. It is a container for a set of strings from a specific origin, also called a map in technical parlance. These strings consist of a key (the origin) and a value (storage bucket id). When a storage shelf is created (by whom or what is discussed below), there are some other features you can set, including:
- Policies used for security checks.
- Whether or not the shelf can be used by scripts that require cross-origin isolation. This, as you can imagine, is important for the Privacy Sandbox where cross-origin isolation can be important to prevent cross-site re-identification of a user.
This is the structure that allows us to partition storage at a level, the storage bucket, that developers can use to manage their storage quotas in a finer-grained way than was previously possible.
Level 4: Storage Buckets
Within each storage shelf there can be multiple storage buckets. Storage buckets have their own proposed API (see below) and are one of the major evolutions of storage occurring beside the Privacy Sandbox. The intention is that this standard will ultimately get merged directly into the Storage Standard.
A storage bucket is a place for storage endpoints (storage types) to “store” data. I say that because, as discussed below, this is the only level of the architecture which the developer can manipulate to manage their use of storage when storage quotas become a constraint. So from a developer’s perspective, this is where and how the data is stored and managed. The “store” is in quotes because a storage bucket doesn’t contain any of that data. The data is stored in whatever storage type the developer chooses to use. All a storage bucket holds is a key value pair with a storage bottle id as the key and the storage endpoint as the value.
Every storage bucket must be associated with a storage endpoint, which is one of the browser storage types we have previously discussed. Figure 2 shows the different types of storage endpoints that are recognized by a storage bucket, their type, and their quota. As is clear from the table, storage buckets are used for all forms of storage (the serviceWorkerRegistrations endpoint is how the bucket connects to the Origin Private File System, which isn’t obvious). The quota for a storage endpoint is a number representing a recommended default storage limit (in bytes) for each storage bucket corresponding to this storage endpoint.
Figure 2 - Types of Storage Endpoints in the Storage Standard

A quota is set to null means one of two things::
- The amount of available storage on a user's device for that storage type can vary depending on factors like the operating system, device limitations, and other applications' storage usage.
- Setting a null quota allows browser vendors and storage API implementations to determine appropriate storage limitations dynamically based on the user's device and system resources.
What it does not mean is that the user can set the quota or that the storage has no restrictions.
There are two kinds of storage buckets.
- A local storage bucket is a bucket for local storage-type data. As you would expect, this data will persist beyond a single session.
- A session storage bucket is where session-type data for a particular website is stored. Session storage data persists until the browser window or tab is closed.
Level 5: Storage Bottles
So finally we are in the storage unit, we’ve have pulled out a bucket, and there are now a series of bottles in the bucket. Are they full of data? Sadly no. There is a lot of empty space in these bottles (or else they are really small). Storage bottles aren’t storage. They contain a single key-value pair that points to a specific location in an appropriate storage type where a specific piece of data is stored.
// create the data for a storage bottle
const user-data = “alvinchipmunk”;
// Store the user data in a storage bottle with the key “user-data”
localStorage.setItem("user-data", user-data);
You can access the key value (to determine if it exists) by making a call to the storage bucket of the storage bottle:
// Get the storage bottle key from your website's logic
const storageBottleKey = "user-data";
// Retrieve the storage bottle (which might involve browser-specific calls) const data = getStorageBottle(storageBottleKey);
// Check if the storage bottle exists and has a value
if (data) {
const userId = data.value;
That isn’t to say you can’t store complex data in a bottle. You can do that by creating complex data structures as a single object and then either writing them to, or retrieving them from, the appropriate storage endpoint. Here is a more complex example using a JSON structure to store multiple elements:
// construct a JSON data structure called userSettings with four elements
const userSettings = {
fontStyle: arial,
fontSize: 16,
fontColor: blue,
showGrid: true,
};
// Store the user settings as a single object as a JSON string
localStorage.setItem("user-settings", JSON.stringify(userSettings));
The Storage Bucket API Provides Access
You may have noticed that nowhere in the code examples is there any constructor like
const bottle = await storage.createStorageBottle(bottleName)
This is a made-up example because there is no createStorageBottle() capability in Chrome. In fact, the architectural elements as currently specified are not something developers can access directly. When the code above calls getStorageBottle(storageBottleKey) it can access the key name for a storage bottle that was automatically created by the system when the user saved a key called “user-data”. But the developer did not actively create the storage bottle - he didn’t have to. All of it is happening in the background, providing the benefits to the developer without forcing them to do all the work of setting up the structures. All the developer has to do is get or write data and all the mechanics happen behind the scenes.
Convenient? Yes. Problematic? Yes The problem is I need to be able to manage storage.
Remember, one of the purposes of the Storage Standard is to allow developers to have more granular control of storage management.
The problem with browser storage prior to the Storage Standard was one of a site running out of storage quota within a browser. If the user ran out of storage quota on their device, the data stored with APIs like IndexedDB or localStorage would get lost without the browser being able to intervene. The original StorageManager interface in the Storage Standard allowed developers to check for storage usage and write exception handlers when storage threatened to get too full. But in that case the browser was limited to an all-or-nothing call. It could only clear storage for that origin completely. This could be problematic because a given site might have multiple applications running in parallel and they would all have data deleted. This could end up causing a degraded or even a disrupted user experience.
So the developers of Chrome have developed an extension of the Storage API called the Storage Buckets API. This API, which has been available since the Chromium 122 release, allows developers to create storage buckets to contain data for specific applications or specific pieces of applications. A developer can create as many storage buckets as they want. When the estimated storage usage approaches the storage quota (using the updated version of the StorageManager interface), the browser may then choose to delete each bucket independently of the other buckets to free up storage space. Developers manage this by specifying an eviction priority to each bucket to ensure that the most valuable data doesn’t get deleted.
Eviction is a tad more complicated because the developer can mark a storage bucket as persistent. In this case, the contents won't be cleared by the user agent without either the data's origin or the user specifically doing so. This includes scenarios such as the user selecting a "Clear Caches" or "Clear Recent History" option. The user will be asked specifically for permission to remove persistent site storage buckets.
As noted earlier, each storage bucket is associated with a specific storage endpoint. An example of this shown below. I have highlighted the two lines of code that make the point:
// Create a storage bucket for emails that are synchronized with the
// server.
const inboxBucket = await navigator.storageBuckets.open('inbox');
const inboxDb = await new Promise(resolve => { const request = inboxBucket.indexedDB.open('messages');
request.onupgradeneeded = () => { /* migration code */ };
request.onsuccess = () => resolve(request.result);
request.onerror = () => reject(request.error); });
As you can see, you first create the bucket and then you tie it to the type of storage endpoint it needs to use.
This storage bucket is the finest-grained unit of storage that developers can control. Bottle management is happening behind the scenes. So going back to our analogy for a moment, when the developer pulls the storage bucket from the storage shelf, the bucket is a closed black box that they cannot open. However, there is a slot in the side where they can stick things into the box they want stored there or to be able to take from sometime later. Moreover, there are five different sizes of boxes on the shelves. The developer chooses the box size that best fits the amount of “stuff” they need to store. When the shelf runs out of room, the developer has to choose which box to get rid of. Sadly, removing items from the box doesn’t reduce the space taken up by the box. So if grandma's valuable jewelry is in with some unimportant papers that are not needed, the developer is SOL and grandma’s jewelry goes bye-bye along with everything else in that box. So it is important for the developer to carefully choose what data to put in which storage bucket.
A Messy Specification
Do you feel that this is a lot of complexity for something that should be relatively easy to understand? Well, you are not alone. I will say this: I have spent more time on this aspect of storage than I have on any other area of browser tech so far, I have been through more rewrites than any other feature as I have continued to try and figure it out and discovered areas that I got wrong the first time. Frankly, I’m not sure I still understand it. I thought it was me but then I found this comment from Maciej Stachowiak from Apple in June 2020 (!) that I want to quote in full because it expresses the frustration I had while writing this post. It can be found in issue #101 in the github repository for the Storage Standard
The terms "storage shed", "storage shelf", "storage bucket" and "storage bottle" are hard to understand. The terms express a size hierarchy, which is pretty clear, but other than that, they don't convey what they mean. Even the size hierarchy is based on a somewhat arbitrary ordering of keys. The ordering of the hierarchy is not motivated in the spec, and the "model" section does not directly explain what they represent.
Here's what I was able to figure out on careful reading:
storage shed: seems to exist solely to distinguish "local" vs "session". Not clear why this is the outermost container. Also, currently redundant with identifier, since any given identifier can only be one of "local" or "session", the comment that this may change does not explain why.
storage shelf: represents the storage for an origin (presumably will change for storage partitioning; will this change the key, or will it add another level of storage hierarchy?)
storage bucket: can't figure out what this represents. Currently it seems there is only one per storage shelf (keyed as "default"), but even from reading the citied issue #2, I can't figure out what a non-default bucket would represent.
storage bottle: represents the storage for a particular storage API
Perhaps something like "storage scope", "origin storage", "???", "endpoint storage"/"API storage" would be more clear? (No suggestion for the bucket because it's not clear what it is). At the very least, an overview explaining what each of the containers represents, and why they are ordered this particular way, would make it easier to understand the spec.
We will stop here for today so I can take some Advil for the headache writing this gave me.
NEXT UP: A Tech Talk on Navigables and Session Histories

WebAssembly and Its Use in The Sandbox
Introduction
WebAssembly, also known as Wasm, is an open W3C standard that was first released in 2015. Wasm is a new type of code that allows native applications written in languages like C++ to run efficiently and portably in a web browser. The term ‘portably’, in this case, means the code can run within any browser context using standard browser APIs without requiring any recoding. Wasm allows applications to run in a browser at the speed they would run as a standard O/S executable. In this way, browsers can handle a whole new class of applications that would otherwise run so slowly as to be unuseable. Equally important, developers don’t have to write any Wasm code. They deliver code in whatever language is supported by Wasm, it is converted into Wasm’s highly-efficient low-level assembly language, then wrapped in a Javascript wrapper. While today a Wasm module has to be called by a JavaScript function, in the future developers will be able to call Wasm modules just like any Javascript executable module with the command “<script type='module_name'>.
I don’t think it takes much imagination to see why Wasm might be important to the Google Privacy Sandbox. Given you are trying to run a large number of parallel auctions in the browser, and in some cases on servers (e.g. bid scoring) in a Trusted Execution Environment, performance at scale becomes critical. Wasm is a perfect solution to this problem. We are talking about Wasm in the section on browser elements, even though it isn’t an “element” in the browser per se, because it will enter into storage element discussions in the next post.
Wasm can quickly become an extremely technical discussion. We are not going to go there for now. Perhaps later in the series I may write a drill down for those who wish to learn more, but I doubt it. Frankly, I could just tell you that Wasm is a performance-enhancing wrapper around typical code that can then be called as a script in the browser and we could move on without missing too much. But you are a relatively technical business reader, and I assume that you might enjoy learning just a tad more about this relatively powerful browser technology when we talk about its use in later posts.
I will start with a discussion of Wasm, what it is, and how it works. Then we’ll discuss how it is being used by FLEDGE Origin Trial participants to implement aspects of the Privacy Sandbox
The Goals of WebAssembly (Wasm)
According to the Mozilla web docs, there were four main design goals for Wasm:
- Be fast, efficient, and portable. WebAssembly code can be executed at near-native speed across different platforms by taking advantage of common hardware capabilities.
- Be readable and debuggable. WebAssembly is a low-level assembly language, but it does have a human-readable text format (the specification for which is still being finalized) that allows code to be written, viewed, and debugged by hand.
- Keep secure. WebAssembly is specified to be run in a safe, sandboxed execution environment. Like other web code, it will enforce the browser's same-origin and permissions policies.
- Don't break the web. WebAssembly is designed so that it plays nicely with other web technologies and maintains backwards compatibility.
The Browser as Virtual Machine
If you think about it a certain way, the browser is nothing more than a sandboxed virtual machine that runs Javascript code and can call a series of APIs. The virtual machine runs CSS and HTML and calls Javascript modules to control aspects of the virtual machine (e.g. the Domain Object Model) or to add functionality to run within the browser.
The problem with Javascript, as with any scripting language, is that it runs more slowly than a typical native application. That level of performance is fine for a wide range of browser-based applications. However there are a variety of use cases and applications where Javascript is not fast enough to be practical. These include games, 3D rendering, VR and augmented reality, and browser-based VPNs, amongst others. Moreover, even if it can run fast enough, the cost of downloading, parsing, and compiling JavaScript can make it prohibitive to use in mobile or other resource-constrained platforms - for example automobiles.
WebAssembly is designed to be a complement to JavaScript for those use cases where JavaScript’s lack of efficiency is problematic. It is a low-level, assembly-like language with a compact binary format. It provides near-native performance. It also provides languages that have low-level memory models, such as C++ and Rust, with a compilation target so that they can run on the web.
There are many great design features of Wasm, but the one that we care about most for this discussion is that Wasm does not require the developer to rewrite their code in a new language. Instead, it takes existing code, converts it to a very fast executing, assembly-level code-like format. It then wraps that fast-running code in a Javascript wrapper so that its functions can be accessed just like for any other JavaScript module. Figure 1 shows an example of how this works for C++:
Figure 1 - The Process By Which C++ Is Converted to a Wasm Javascript Module
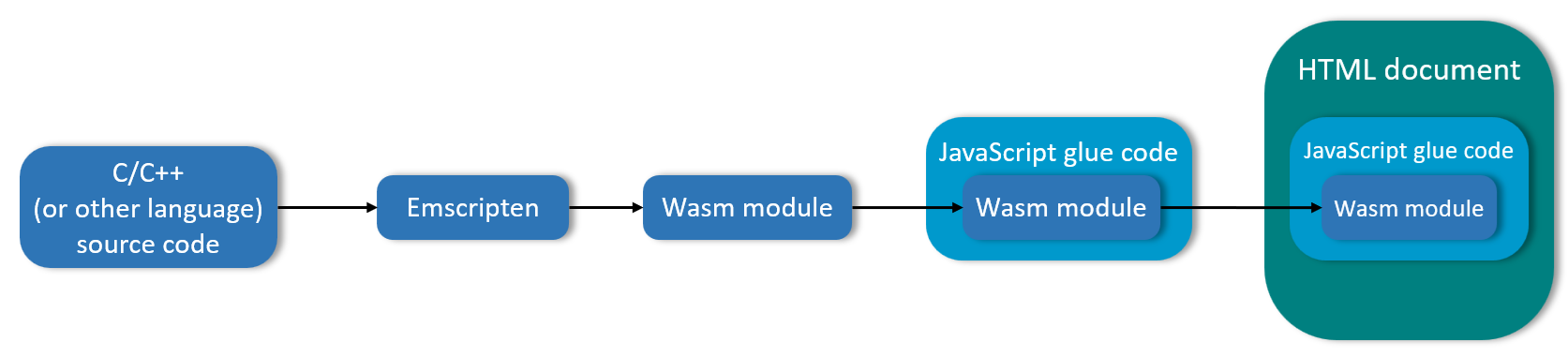
The developer’s original C++ code is run through a Wasm encoder/converter that compiles the C++ into Wasm binary format. For those who are curious, one of the most common tools for this is Emscripten. Once the Wasm module is created, it is then wrapped in some Javascript “glue code” - basically it is called by a JavaScript function - and then runs inside the browser.
We call this approach to architecture a virtual instruction set architecture (virtual ISA). A virtual ISA emulates the instruction set of one processor type by hardware, firmware and/or software running on a different processor type. It can apply emulation to individual programs or on entire virtual machines. Wasm basically emulates the native compiler for C++ to create an equivalent kind of bytecode that can be run within the browser - so it is emulating, for example, the Windows instruction set on an Intel processor but in a way that it can run on the browser “virtual machines” instruction set. That is not necessarily a perfectly accurate technical description, but it gets at the basic concept.
WebAssembly Text Format
Now, if you have ever looked at assembly language (Figure 2) you will see that it is anything but easily comprehensible to the average human. If you understand what you are seeing here to the left of all the semi-colons, 20 points to Gryffindor! In other words, you are not expected to interpret the code, just get a sense of how inhuman it is.
Figure 2 - An Example of Windows Assembly Code for Adding Two to a Prior Number
; Add 2 to a number starting at 0 and store the result in register EAX
mov eax, 0 ; Move the value 0 into register EAX (initial number)
mov ebx, 2 ; Move the value 2 to register EBX (number to add)
add eax, ebx ; Add the value in EBX (2) to EAX (0), storing the result in EAX
; Optional: Print the result using system call (Interrupt 21h)
; This part requires additional code for setting up parameters and handling return values.
; Exit the program
mov eax, 4 ; System call for exiting (INT 21h with AH=4)
xor ebx, ebx ; Set EBX to 0 (optional, some programs expect it)
int 21h ; Interrupt 21h to exit the program
Sometimes developers want to write Wasm code directly (versus compiling code written in another language) or need to examine Wasm code for debugging purposes. In those cases, even though they could read and write assembler, they probably don’t want to because it is a very “wordy”, time-consuming, and painful way to code - even for experienced developers. (Trust me on this one. I did it long ago on Intel 8086 chips and have been grateful that I haven’t had to do it in the 40 years since.). Thus, the standard provides a text-based format that works with text editors and browser developer tools. Figure 3 shows an example of such code that performs a similar task as shown in Figure 2.
Figure 3: A Wasm Text Function Adding Two to a Prior Number
The text- version of the module called “addTwo” is on the left side, and its Wasm representation on the right-hand side. Don’t worry about how the code works or what the words mean. Just note how much more code is required for the WebAssembly-encoded version.
We then wrap Wasm in a very simple JavaScript function and call it. You can see the addTwo module embedded in a JavaScript function on the left-hand side and the output of the function on the right hand side of Figure 4.
Figure 4 - Output of the Wasm Function in Five Lines of JavaScript Code
Thus Wasm coding can be very efficient, even when it has to be done by hand. It starts to feel a lot like coding in JavaScript, but it results in substantially higher-performing code.
WASM in the Privacy Sandbox
As mentioned earlier in the post, it is easy to imagine why Wasm is an important technology leveraged by the Privacy Sandbox. It allows code to run at native speeds in the browser for things like adding interest groups, running auctions, and bidding.
Let’s take interest groups in the Protected Audience API. These were introduced in the post on navigators, promises, and beacons. Interest groups, as a reminder, are audiences that are stored in the browser’s partitioned storage as a SQLite file, keyed by owner and origin - so they are partitioned.
What is important about interest groups for this discussion is that in the definition of interest groups in the Protected Audience explainer there is a field (actually, to be technically accurate, a key in a key-value pair) in the associated metadata called biddingWasmHelperURL. This metadata field is actually a helper for a key function in the bidding process called, practically enough, generateBid. The biddingWasmHelperURL field allows the owner of the interest group to call computationally-expensive subroutines in WebAssembly rather than embedding that code in its standard bidding logic. That way advertisers or DSPs who want to bid can run high-overhead processes in the browser fast enough to respond before the bid request times out. An example would be using sophisticated logic to evaluate bid requests to determine if they wish to participate in a specific auction.
A second reason for using Wasm is the way bidding is implemented in Chrome on a mobile platform. In mobile all Protected Audience JavaScript operations use a single thread. Once a process is assigned, Chrome creates something called an executor for the script, which starts loading the JavaScript and Wasm URLs. Because bidders share processes based on their origin, all of a single buyer origin’s interest groups are assigned an executor (newly created or reused) at once.
What that means is all the buyer’s bidding logic for every interest group in a specific auction loads at the same time, meaning this code has to potentially run in parallel if each interest group has different bidding logic. Thus this is another instance where computational performance, and thus Wasm, become critical.
Wasm is used throughout the Privacy Sandbox for similar applications. For example, here is an example from the Attribution Reporting API repository that is part of code that is validating event-level reporting:
Figure 5: Sample Code that Calls Wasm User Defined Functions in the Attribution Reporting API
"node_modules/@webassemblyjs/wasm-edit": {
"version": "1.11.6",
"resolved": "https://registry.npmjs.org/@webassemblyjs/wasm-edit/-/wasm-edit-1.11.6.tgz",
"integrity": "sha512-Ybn2I6fnfIGuCR+Faaz7YcvtBKxvoLV3Lebn1tM4o/IAJzmi9AWYIPWpyBfU8cC+JxAO57bk4+zdsTjJR+VTOw==",
"dev": true,
"dependencies": { "@webassemblyjs/ast": "1.11.6",
"@webassemblyjs/helper-buffer": "1.11.6",
"@webassemblyjs/helper-wasm-bytecode": "1.11.6",
"@webassemblyjs/helper-wasm-section": "1.11.6",
"@webassemblyjs/wasm-gen": "1.11.6",
"@webassemblyjs/wasm-opt": "1.11.6",
"@webassemblyjs/wasm-parser": "1.11.6",
"@webassemblyjs/wast-printer": "1.11.6" }
It’s not important to know what the code is doing - I just want you to see the extent to which Wasm is drawn upon for this one module. You can look throughout the code in the repository and see many more examples of this.
One last example - this time on the service side of Protected Audiences. I talked about the Key Management Services in one of my earliest posts on Sandbox architecture. Each key management service hosts a key-management server in a Trusted Execution Environment (TEE). These servers store and manage encryption keys for each origin (i.e. advertiser, publisher, etc) in a separate, secure partition (there’s that term again, but used in a new context). This is because encryption keys are highly sensitive and if accessed by an evil actor could do untold damage to the origin whose keys have been accessed. With multiple parties running multiple bids and auctions on the server, there could be hundreds, maybe thousands, of concurrent calls from each partition for the code to generate, update, or retrieve a particular origin’s encryption keys. It is also possible that each partition runs slightly different versions of the code based on their business requirements .
As a result, the Protected Auction Services API, which specifies much of the server side of the Protected Audiences API, uses what are called user-defined functions to handle these capabilities. User defined functions can be written in JavaScript or Wasm. Whether Wasm is selected depends on the performance needs of the origin, which in turn depends on their hardware configuration and their scale of business, among other things. Figure 6 shows an example of code from the Protected Auction Services API repository. The code creates a Wasm function that generates a UDF delta file (don’t worry about what that is right now).
Figure 6 - Example of Wasm Text-Based Code Used in the Protected Auction Services API
def cc_inline_wasm_udf_delta(
name,
srcs,
custom_udf_js,
custom_udf_js_handler = "HandleRequest",
output_file_name = "DELTA_0000000000000005",
logical_commit_time = None,
udf_tool = "//tools/udf/udf_generator:udf_delta_file_generator",
deps = [],
tags = ["manual"],
linkopts = []):
"""Generate a JS + inline WASM UDF delta file and put it under dist/ directory
Performs the following steps:
1. Takes a C++ source file and uses emscripten to compile it to inline WASM + JS.
2. The generated JS file is then prepended to the custom udf JS.
3. The final JS file is used to generate a UDF delta file.
We’ll leave it there for now.
Next Up: The Privacy Sandbox Changes to Browser Storage

Storage Before The Sandbox
Introduction
Now that we have covered cookies in their particular, isolated post (does that mean we have put them into a blog partition?), it is time to explore partitioned storage in more detail.
The problem is that in reality, there is no unique storage element that represents partitioned storage, per se. Rather, partitioning is a concept that has evolved as a means of reducing the risk surface around cross-site tracking. Remember the most important design principle underlying the Privacy Sandbox is to prevent, as much as possible, any form of cross-site tracking at the individual browser level. Partitioning is one of the fundamental design approaches that Google and other browser developers have standardized upon to achieve this goal.
Partitioning as a design concept has been used in browsers for a long time. Most forms of storage today are partitioned by top-level domain (TLD). When we talk about partitioning in terms of the Google Privacy Sandbox, what we are actually talking about is enhanced partitioning, which comes in two flavors:
- Adding a partition key where none existed before
- Adding additional keys beyond the TLD to restrict the scope of access by third-party elements on a web page or to specific subdomains
I introduced the concept of partitioned storage in the post on fenced frames. In the next few posts, we are going to delve more deeply into how this approach is used across all of Chrome storage elements to support the goals of the Privacy Sandbox. We’ll start with how the various storage elements behaved prior to the notion of enhanced partitioning. In the next post we will take a slight detour into another browser technology that supports the Sandbox: Web Assembly or WASM. Finally, we’ll explore the enhancements that the Privacy Sandbox makes to storage and their implications.
Session and Local Storage
A unique page session gets created and assigned to a particular tab when a tab is opened in Chrome. A page session lasts as long as the tab or browser is open. It also survives both page reloads and restores (for example when the browser crashes).
Each session has two kinds of storage: session storage and local storage. Session storage only maintains items until the session ends and then clears them. Local storage maintains small amounts of data that a website may need to use across sessions, such as user preferences, login state, or application state. Local storage has a limited storage quota (typically around 5MB). So it is not ideal for storing large amounts of data.
Why not use cookies instead? There are, in my mind, three main reasons:
- Limited Storage. Cookies have even more limited storage than local storage - about 4KB per cookie. This makes them unsuitable for larger data like application state information.
- Security Issues. Cookies are sent with every HTTP request to the server, which can be a security risk if they contain sensitive information.
- Performance. Local storage doesn't send data with every request to the server, improving website performance.
Going back to the definition of a session, what happens when, like me, you have 80,000 tabs open (let’s not exaggerate, it's actually only 94) and you accidentally (or purposely) open multiple tabs to the same or different pages on a single site? Chrome treats those as part of the same session. This allows any data stored during your browsing session, like cookies or session storage information to be accessible by both tabs. However, each tab can navigate independently. You can browse different pages within the same site on each tab without affecting the other.
This works because Chrome uses the origin as a key for partitioning session data. It turns out this is also the key that is used to isolate content stored in local or session storage. Thus even before the Privacy Sandbox, local and session storage were partitioned.
An origin-based partition, however, is not ideal from a privacy perspective. This is because that single key can be used not just on the top-level domain but on all subdomains. Now you might ask, why is that such a big deal? I’m only on one site. I obviously have a reason to be there if I am floating around enough to hit different subdomains (e.g. financeco.com vs. mybanking.financeco.com). And moreover, sites use Google Analytics or other analytics vendors, to learn about my movements within the site to help optimize my user experience. So why the big deal?
Well, I may not think it is a big deal (and I don’t), but others might. For example, I am on mycommercesite.com and while shopping I visit a specific seller’s subdomain, sexy.mycommercesite.com, that sells sexually explicit materials like videos or games. I really don’t want the site to track me across those two subdomains because I don’t want them popping emails into my inbox at a later time with recommendations for sexually-explicit items. Moreover, in today’s cookie banners, you can opt-out of analytics cookies, so that sites can’t use analytics to understand your behavior patterns. Thus, even within a site tracking is considered a privacy violation if not permissioned by the user.
So why not then key session and local storage to sexy.mycommercesite.com when that page loads, thus treating it as the origin? Alternatively, if I land there first and then go to mycommercesite.com, why wouldn’t I make the key the subdomain? The answer is you can’t. When the specification says you have to key to the top-level domain (TLD), that’s all you can do. You can’t treat a subdomain, also known as a TLD+1, as the TLD.
Thus Google considers origin (top-level domain) partitioning of session and local storage to provide a privacy risk.
SQL and NoSQL Databases
The Three Amigos: SQLLite, WebSQL, and IndexBD
The next major form of browser storage are SQL and NoSQL databases. SQLite and WebSQL are/were SQL databases, as their names imply. IndexedDB is a NoSQL database. Now you might say, those are two different types of storage, which I would generally agree with. Except in this case, SQLite underlies both WebSQL and IndexedDB. How that is possible requires delving a bit into the history of client-side databases.
SQLite is a relational database engine. It is not a standalone app like PostgreSQL that you access via a desktop SQL client (e.g. dbVisualizer) and read the data contained in a set of tables. It is a library that software developers embed in their web apps, and thus is part of a class of embedded databases. It was invented in 2000 by Richard Hipp of General Dynamics. SQLite is not a browser-specific technology. It is embedded in a wide array of applications. However, it is used extensively in web development. Chrome installs it with the browser and depends on it directly to store data like user browsing history.
WebSQL is a deprecated web browser API that provided a database capability within browsers. It can be queried using SQL tools. WebSQL was introduced as part of Google Chrome in 2009. However, Mozilla developers were intensely opposed to it. In fact, WebSQL was never implemented in FireFox. Only Chrome, Safari, Internet Explorer/Edge, and a few others did implement it. Mozilla’s objections had to do with the fact that WebSQL was basically a wrapper around SQLite. These objections were stated in a 2010 blog post on mozilla.org:
We think SQLite is an extremely useful technology for applications, and make it available for Firefox extensions and trusted code. We don’t think it is the right basis for an API exposed to general web content, not least of all because there isn’t a credible, widely accepted standard that subsets SQL in a useful way. Additionally, we don’t want changes to SQLite to affect the web later, and don’t think harnessing major browser releases (and a web standard) to SQLite is prudent.
Mozilla’s preferred option was IndexedDB, and it ultimately has supplanted WebSQL in all major browsers. Now it turns out that IndexDB is another child of SQLite. Well sort-of. IndexedDB on Firefox, Safari and Edge all use SQLite. But leave it to Google to use a different embedded database called LevelDB. LevelDB was invented by Google fellows Jeffrey Dean and Sanjay Ghemawat in 2011. LevelDB, unlike SQLite, is not a SQL database. It does not have a relational model and does not support SQL queries. You can therefore understand why Google chose to use it over SQLite. Why use a SQL backend for a NoSQL front-end? There are performance and other issues with using a SQL backend. Having LevelDB as the embedded database helped avoid these issues. For example, Google provided benchmarks in 2011 comparing LevelDB's performance to SQLite, and showed that it outperforms SQLite in write operations and sequential-order read operations
IndexedDB in Chrome is both an API and an abstraction layer built on top of LevelDB. As you might expect, an abstraction layer abstracts out certain functionality from another object to shield developers from unnecessary complexity. In essence, IndexedDB acts as an intermediary between web developers and the underlying LevelDB storage engine. It provides a higher-level abstraction with a more user-friendly data model and operations while still leveraging the core functionality of LevelDB for efficient data storage and retrieval.
With that introduction, let’s drill further into SQLite and IndexedDB and their status prior to the Privacy Sandbox. We’ll ignore WebSQL because as of Chrome 123 it is no longer supported, even for backwards compatibility.
SQLite
SQLite stores each of its databases as a file. The whole database (definitions, tables, indices, and the data itself) consists of a single cross-platform file on a client machine, allowing several processes or threads to access the same database concurrently. These files are not partitioned by origin key, nor do they require any kind of authentication with usernames and passwords. As I did in an earlier post, you can find a SQLite viewer extension and query the database directly. Here’s a second example where I queried the Chrome preferences file with the simple query at the top. I didn’t have to log in - just opened the file in the C:\Users\arthu\AppData\Local\Google\Chrome\User Data\Default directory. You can see all the tables in the database on the left side of the screen and no doubt will note that I have direct access to very personal information, like my credit card data.
Figure 1: Another View to a SQLite File in Chrome

However, access to these files is controlled by the file system. So unless a web application can break through other security protections Chrome employs, such as running in the Windows Sandbox or enforcing sites isolation in memory (don’t worry about what these are just know they are there), Chrome ensures security and privacy of the SQLite files.
IndexedDB
IndexedDB, as previously mentioned, is a client-side, NoSQL, high performance database that allows web applications to store and retrieve data structured into key-value pairs. It is used when large amounts of data need to be handled efficiently within the browser. This mechanism allows applications that depend on such data can retrieve it and render it on-screen in a fashion that does not degrade the user experience. IndexedDB also allows developers to cache this data locally so it can be available offline.
IndexedDB is partitioned by top-level domain. Each domain has its own database where it stores data, and each database is stored in its own subdirectory under the default directory (Figure 2). The database, without special approaches, does not have any user authorization. That is to say, you don’t need a username or password to access the data in the database. The way data is secured is that any request to access an IndexDB database must come from the top-level domain which created the database. There are ways to create a mechanic to create tighter security for IndeDB databases, but they are not immediately relevant to the Privacy Sandbox discussion.
Figure 2 - IndexedDB File for GoDaddy Shown In Directory and Contents of File Shown on GoDaddy Site

Origin Private File System
The Origin Private File System (OPFS) is a very different type of storage from anything we have discussed so far. Unlike local storage or IndexedDB, which use an optimized object/key-value storage mechanism, OFPS enables byte-by-byte access, file streaming, and low-level file manipulation. OFPS uses a sandboxed file system, so in that sense it is “partitioned”, although that is a misuse of the term. It is private to the origin of the page (website or embedded element) and not visible to the user. It is intended to allow web apps to store and manipulate files in their very own origin-specific file system on the client, and is particularly useful where high performance/high throughput files operations are required. To give a sense of the difference, there are estimates that OPFS is 3-4x faster at disk I/O in comparison to IndexedDB. Equally important, it provides more efficient use of resources as well as enhanced security and privacy.
Remember we talked about web workers in an earlier post? If not, you may want to go back and review what a web worker is in order to understand the next statement. Since OFPS works with local files on disk, it has read() and write() methods to access data from and write data to the local hard drive. The read() and write() methods are only available inside a web worker. This is because read() and write() are synchronous methods (they run as called) and if they were to run on the main thread, for example calling or writing continuously streaming data, they could significantly impact app performance. So they run in a web worker to allow them to manipulate data on and off the disk in parallel with the main browser actions.
That’s about as deep as I want to go into the technical aspects of OFPS except for one other item. OFPS can write files anywhere on the hard drive, so there is no specific subdirectory under Chrome where you will find OFPS files.
Application Cache
The browser application cache (cache) stores data from websites for use by documents and web applications even when a network connection is unavailable. This is a concept that almost every user of the web is familiar with, as at some point or another they have been asked to ‘clear their cache’. The cache also provides speed. Since a page has already been downloaded and cached, its resources come straight from the disk.
The cache is basically partitioned by origin. Each site has its own files in the C:\Users\arthu\AppData\Local\Google\Chrome\User Data\Default\Cache\Cache_Data directory (on windows). The files are stored in a binary format that is described here for those who want to drill further.
Figure 3 shows an example. Here I have used a binary converter to convert one of the files to visualizable form. As you can see, I can easily access the image from this site.
Figure 3 - Reading an Application Cache File from the Local Hard Drive

I can access this from my local hard drive as I have direct access to the file system. As a rule, the cache from one web site cannot be viewed unless the request has the origin site in the request header. However, that level of partitioning is not an impervious solution. There are numerous attacks that an evil actor can use - cross-site scripting, local storage hijacking, and cache poisoning to name a few - to gain access to other site’s cache elements and create a cross-site user profile. Existing mechanics can mitigate some of these, but they are not foolproof. We will discuss what Chrome has done to improve cache security and isolation in the post where we talk about the Cache API, which replaced a previous technology called AppCache in 2020. Given its origin date, Cache API is not part of the Privacy Sandbox specifically, but a technology on which it depends.
BLOB URL Storage
A BLOB is a Binary Large Object. BLOBS can be all sorts of files - big images, audio, video, or documents. In fact, when you download a file from a website, that is most likely downloaded by Chrome as a BLOB. BLOBs are stored in cache. However they can often be too big for the available memory, so they are sliced and the portions not being processed are temporarily stored on disk. Every web client must maintain a BLOB URL store, which is a key-value map where the key is a valid URL string and the value is the URL that points to the blob. Blob URLs look like:
blob:http://example.com/550e8400-e29b-41d4-a716-446655440000
While a BLOB is keyed to its origin. BLOB storage is not partitioned. BLOBS tend to reside in the browser’s cache temporarily and are often sliced, so do not really represent a likely attack surface for cross-site tracking. There are some subtleties here, as there are cache management capabilities that control how and for how long a BLOB is kept in the cache, but they do not change the basic rationale for why BLOB storage is not partitioned.
Done for today.
Next Post: Web Assembly and SQLite

Browser Elements Part 2: CHIPS
Introduction to Cookies Having Independent Partition State
Cookies Having Independent Partitioned State (CHIPS) is the first of the five adaptations of browser storage for the Privacy Sandbox we will examine. But in order to talk about CHIPS, why it was needed, and what it does, we must talk about the technology it builds upon: cookies. Now cookies are a well understood technology and I absolutely do not want to write a primer on cookies given the focus should be on what comes next. But I cannot figure out a way to write about CHIPS without delving into cookies in some (what is for me) moderate detail.
Moreover, I have been into Internet technology since 1994 when cookies were first invented at Netscape and I was directly dealing with Netscape on various web standards. Yet until now I knew relatively little of what I will discuss in the next paragraphs. Which leads me to believe that many product and business executives in adTech may not know as much as I would like to believe.
So if you know cookies like the contents of a bag of Chips Ahoy that you snarfed down as a kid, then skip this section and go directly to the discussion of CHIPS. But if not, then stay with me as I review the history and working of browser cookies.
Browser Cookies 101
Mechanics of Browser Cookies
Browser cookies are almost as old as the web itself. Browser cookies, specifically, were first “invented” at Netscape in 1994 by Lou Montulli in response to a request from Vincent Cerf and John Keinsin at MCI who needed to store information for an ecommerce website they were building but for which they didn’t want to store all the state information on a central server. Browser cookies were a new application of what was already an established concept called magic cookies, which were widely used in Unix by the time Netscape came along. Magic cookies are code tokens that contain small amounts of data. They are used to identify a particular event or a "handle, transaction ID, or other token of agreement between cooperating programs."
The analogy for magic cookies I like to use is the use of computer magnetic tape rings to control printing at my business school. At the time, we were on a small DEC VAX 700 mainframe. When assignments were due (and nothing was online then), printing the output of assignments became a bottleneck and printing could take hours. The head of IT used computer magnetic tape rings to give printing rights. If you had one of the rings you could print. If you didn’t, you had to wait until you did. That way printing was fast and you didn't have to wait an unknown amount of time for your assignment to pop out of the printer. This is basically the use of these rings as a “token of agreement” between two cooperating items: a human and a printer. The “content” of the token, if you stretch your imagination, was a binary 0 or 1 that allowed one resource to access another. That is the basic notion behind magic cookies.
Lou Montulli took this notion one step further and used the cookie concept to store some small amount of stateful information about a customer’s interaction with a site in the browser (e.g. what items were abandoned in a shopping cart). This could then be accessed by the site’s owner (so a first-party cookie) the next time that particular browser/user visited the site to recreate the last known state. Cookies were built into Mosaic Netscape V0.9beta in October, 1994, and then into Internet Explorer V2 in 1995. The first cookie standard was issued via the Internet Engineering Task Force in 1997 as RFC 2109. It was superseded by the current specification, RFC 2965, in 2000.
Figure 1 shows the basic mechanic of how cookies are created and placed in the browser, and later how they are accessed from the browser.
Figure 1- The Basic Mechanics of Setting and Retrieving a Browser Cookie.

Figure 1a: The Initial Request to the Web Server and the Response Setting the Cookie

Figure 1b: On the next request from the browser, the request header includes the cookie
In Figure 1a, a browser makes an initial call to a server for www.theprivacysandbox.com to render a page. The server for theprivacysandbox.com checks to see whether a cookie already exists on the site via a Javascript call (for example) and if it doesn’t find a cookie it sends a Set-Cookie command in its response header. Then based on the user’s activities it may set other cookies on their browser for future use. In browsers the limit on cookies that can be stored by a single domain is 1,800 leaving plenty of room for various uses of cookies within an application.
With every subsequent request to the server, the browser sends all previously stored and appropriately designated cookies back to the server using the cookie header it has set. It uses the information in those tokens to take action or make a resource available.
A Set-Cookie HTTP response header looks something like this:
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: __Host-example=34d8g; SameSite=None; Secure; Path=/;
Note the switches SameSite, Secure, and Path. These are important to understand as we get into CHIPS. While I really do not want to delve into these in any big way, I need to provide you with enough information for you to understand the changes that CHIPS has made to ensure better privacy.
Cookie Attributes
Cookie Lifetimes: Expires or Max-age Attributes
There are two basic cookies. Session cookies, like sessions, only last for the duration of a browser session (and are not tied to a specific tab in a multi-tab browser session). Permanent cookies, on the other hand, expire at a specific date or when they reach a certain age relative to their initial creation with Set-Cookie. Expires or Max-age are the two different switches which can be used to set a lifetime for permanent /cookies.
Restricting Cookie Access: Secure and HttpOnly Attributes
It is important to restrict access to cookies by unintended third-parties or scripts. There are two attributes that help with this. A cookie with the Secure attribute is only sent to the server with an encrypted request over the HTTPS protocol. It's never sent with unsecured HTTP (except when it is on a localhost).
A cookie with the HttpOnly attribute is inaccessible to the JavaScript Document.cookie API. It is only sent to the server and remains there. Keeping the cookie working only on the server when the application is server-based reduces the surface for cross-site scripting (XSS) attacks.
Cookie Scope: Domain and Path Attributes
The scope of a cookie is what sites (origins) or subdomains it applies to. This makes it easy to apply different policies and behaviors to different subdomains within a larger site
The Domain attribute which sites or subdomains a cookie can apply to. Let’s imagine how this might work for www.mypublication.com. mypublication.com content is free, but there is also a paid subdomain behind a firewall allnews.mypublication.com.
If the Domain attribute is not set, then the cookie will only apply to mypublication.com. But if the Domain attribute is set as Domain = mypublication.com then the cookie applies to both mypublication.com and its subdomain of allnews.mypublication.com.
The Path attribute is similar, but it sets the scope of a cookie based on the URL path. For example, it turns out allnews.mypublication.com has two subdirectories: allnews.mypublication.com/politics and allnews.mypublication.com/sports. The politics section has a cookie that tells my server whether or not you are a Republican, Democrat, or Independent so it can customize the news it displays for you. The sports section has a cookie that tells the server your favorite teams so it can customize that information for the reader. In this case, each cookie would have a Path command - one would be Path = /politics the other Path =/sports and the appropriate cookie would only be sent to the server if the request came from a URL containing the correct path.
Cookie Security: Secure and SameSite Attributes
The Secure attribute restricts when a browser sends the cookie back to the server. It essentially ensures the cookie is only transmitted over encrypted connections, specifically those using HTTPS (Hypertext Transfer Protocol Secure). This means the communication between the browser and the server is encrypted, making it more difficult for attackers to intercept the cookie data.
The SameSite attribute is a relatively recent addition to cookie functionality and plays a crucial role in mitigating Cross-Site Request Forgery (CSRF) attacks. It allows the server to specify whether a cookie should be sent along with requests made to different websites (cross-site requests). There are three setting options:
- Only send a cookie when the request is from the origin site,
- Include a cookie in cross-site requests that are initiated through normal user actions like clicking a link
- The cookie can be sent with all requests, but only if the Secure attribute is set
Cookie Prefixes
This is a deep dive area into cookies that I would prefer not to cover. But there is an element in CHIPS that refers to cookie prefixes so I will cover them quickly here.
As cookies are implemented today, a server can't confirm that a cookie was set from a secure origin or even tell where a cookie was originally set. An evil actor could set a cookie on a subdomain with the Domain attribute, which gives access to that cookie on all other subdomains. This leaves the application open to what is known as a session fixation attack.
To counter this, the browser designers created cookie prefixes to assert specific facts about the cookie. Two prefixes are available:
- __Host-. A cookie with this prefix is accepted in a Set-Cookie header only if it's also marked with the Secure attribute, was sent from a secure origin, does not include a Domain attribute, and has the Path attribute set to /. This way, these cookies can be seen as "domain-locked".
- __Secure-. A cookie with this prefix is accepted in a Set-Cookie header only if it's marked with the Secure attribute and was sent from a secure origin. This is weaker than the __Host- prefix.
The browser will reject cookies with these prefixes that don't comply with their restrictions.
The Privacy Risks of Third-Party Cookies
The discussion above spoke specifically to first-party cookies. But it also applies to third-party cookies, with the exception that in the case of third-party cookies the publisher has to put some code on the page (the ever-present “pixel” as it is called in adTech) to allow the third-party to set a cookie on the page.
Why, you might ask, do I care about third-party cookies when the whole point of Google Privacy Sandbox is that third-party cookies are being deprecated? As mentioned in my previous post, while third-party advertising cookies may be deprecated, there are other use cases for third-party cookies that will continue. Some examples are:
- Website Analytics. One of the most common uses for third-party cookies by publishers and advertisers is to allow one or more third-party analytics partners to track user behavior where their ads are displayed on their website (e.g., page views, clicks, demographics).
- Embedded Services. Many sites use embedded services from third-parties to enhance their functionality, such as map services or third-party chat embeds. Chat embeds, for example, send information about the user's device and browsing environment to the chat service. This can help optimize the chat window's display and functionality.
- Content Personalization. Website owners can use third-party services to personalize content for users based on their browsing behavior or preferences. This can involve A/B testing different layouts or content variations.
- Session Management Across Subdomains. Some websites use subdomains for specific functionalities (e.g., shop.example.com for an e-commerce store). Third-party cookies can help maintain a consistent user session across these subdomains.
- Shopping Cart Persistence. eCommerce websites leverage third-party cookies to maintain abandoned shopping cart state when users leave their website and return later.
- Content Delivery Networks. CDNs use cookies to track user behavior and optimize content delivery based on factors like location or device type. This can involve setting a cookie to identify the CDN server that served the content to the user.
- Fraud Detection and Prevention. E-commerce websites can utilize third-party fraud detection services to identify and prevent fraudulent transactions. These services might use cookies to track user behavior and identify suspicious activity patterns.
- Maintaining Site Settings. Many sites use cookies to maintain state on site settings. For example, a site with multiple language options might use third-party cookies to remember the user's preferred language.
These use cases, since they are not intended to track an individual across sites, do not present a direct challenge to user privacy. However they could, if used by an incompetent or evil actor, be employed to perform cross-site tracking. That is why Cookies Having Independent Partitioned State (CHIPS) was felt important enough to include in the Privacy Sandbox platform, even though the specification and use of CHIPS applies to sites whether or not they use the Privacy Sandbox.
How CHIPS Works
Let’s examine the threat to privacy posed by traditional third-party cookies and then examine how CHIPS reduces that exposure (Figure 2)
Figure 2 shows the two different cases. In the first case (Figure 2a), there are two sites both of which use the same chatbot vendor. The chatbot vendor places a tracking pixel and cookie on both sites in order to identify browser features to ensure proper functioning of the chatbot. Without any further protection, the chatbot5 vendor has access to the cookie on both sites when the call is made and the pixel fires. It is the same cookie and collects the same type of data on both sites. That data can then be stored in a single data store and combined to create a cross-site profile of a user. Basically, the browser’s activity is considered the single entity for which data is collected.
Figure 2: Mechanics of Cookies With and Without CHIPS

Figure 2a: How Cookies Work Today without CHIPS

Figure 2b: How Cookies Work with the Partition Attribute Set
The fix to this is to create what is called a partitioned cookie. A partitioned cookie is one that is keyed to its top-level site and cannot be connected to cookies from another site because they sit in partitioned space and can only be accessed by a call from the top-level site. So if a third party vendor sets a cookie on myfirstsite.com it is keyed for that site. When they store a second cookie on mysecondsite.com, it is keyed for the new site. It is not the same cookie and there is no easy way for the information contained in the two cookies to be brought together. When I request data using the cookie on myfirstsite.com, it can only send me back that data and have it stored with data for myfirstsite.com
“But wait!”, you say. “That doesn’t stop me from tracking a user across sites. For example (Figure 3), I can have a user in Browser A buying shoes from myfirstsite.com. I query that cookie and bring that back into my database as the first row with Cookie ID = 123, UserID = BrowserA, site = myfirstsite.com, action = purchase, item = shoes. That same user then goes to mysecondsite.com and buys a dress. Now I have a second row with the data Cookie ID = 456, UserID = BrowserA, site = mysecondsite.com, action = purchase, item = dress. In my database, I can now use Browser A as the match key and build a profile. I have two separate partitioned cookies, but I can still create a cross-site profile. So how does CHIPS help?
Figure 3 - Why Cross-Site Tracking Can’t Happen With CHIPS

Figure 3a: This data capture would allow cross-site tracking. Why can’t I do this?

Figure 3b: CHIPS works because cookies don’t capture user or browser information that could be used to link the two data points.
Very simply, many third-party cookies are not able capture a specific browser ID or other user information from the site on which they are embedded. While browsers might provide some information about the user's client , it's often obfuscated and not reliable for user identification across sites, especially if privacy settings are strict. All the third-party provider has is their cookie ID. Given that, two cookies from two different sites cannot be recognized as the same browser/user. Thus privacy is ensured.
CHIPS adds a new attribute to the Set-Cookie HTTP response header called Partitioned. So the same Set-Cookie header as before would now look like:
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: __Host-example=34d8g; SameSite=None; Secure; Path=/; Partitioned
Note that when a partitioned cookie is used, the Secure attribute must be set so that cookie is only sent to the server with an encrypted request over the HTTPS protocol. It is also recommended that developers use the __Host prefix when setting partitioned cookies in order to bind them to the hostname (and not the registrable domain).
CHIPS Still Allows for Unpartitioned Cookies In Transition
There is one important element to note about CHIPS. Right now CHIPS requires the Partitioned attribute to create partitioned cookies. It is effectively an opt-in in a world where unpartitioned cookies still exist. Google took this approach for a couple of reasons
- There are a number of embedded services which expect an unpartitioned cookie and which may behave in unexpected ways with partitioned cookies without time to adapt to and debug their impact on the application.
- Firefox and Safari had already attempted to require partitioned cookies and this has created some of the problems that the use of the Partitioned “opt in” is intended to avoid while vendors transition to partitioned cookies.
There are some other subtleties/implications of cookies to mention that I found to be intellectually fascinating. Briefly they include:
- Memory Limitations. As mentioned previously, today there is an 1,800 cookie limit per domain. Given the proliferation of cookies, its impact on storage, and also the potential for cross-partition leaks with this much information, the storage space per domain has been proposed to be limited to 10 kibibytes.
Never heard of a kibibyte? Neither had I, but here is the definition:
A kibibyte is 1,024 bytes. This compares to a kilobyte which is actually 1,000 bytes.
Author’s stream of consciousness aside: Really? For 50 years, I thought a kilobyte equaled 1,024 bytes. I mean, I was there when computer memory on an Atari was 256 bytes! How could I have been so wrong for so long?
Moving on. There is a second proposed limit. Cookies should be limited to 10 cookies per partition per domain. Data analyzed from millions of browsers indicates that this will cover 99% of all use cases. You can see a discussion of this issue in the CHIPS Github repository here.
- Cookie Deletion. When clearing cookies, the browser/client should clear all cookies available to that third-party in the partition for the current top-level site alone. It must not clear the third-party's cookies in other partitions.
Browsers may choose to provide user controls to clear individual partitions of a site’s cookies.
Top-level sites should not be able to clear the third-parties' cookies in their partition. This would provide a potential attack vector for top-level sites to interfere with code running in third-party frames
- Impacts on Extensions. Extensions in some browsers are capable of reading cookies (for sites they have host permission) in background contexts using a JavaScript API (e.g. Chrome, Firefox). When extension pages load subresources from other sites, the partition key used to determine which Partitioned cookies should be included in requests must be the site of the topmost-level frame which is not an extension URL if the extension has host permissions for that frame. Otherwise the partition key should be the extension URL.
- Impacts on Service Workers. There are some, but we haven’t covered service workers in the discussion so we’ll skip this for now.
If you wish to learn more about these details, see the CHIPS explainer in the CHIPS Github repository or the very well-written draft specification from Dylan Cutler of Google.

Browser Storage Part 1: Storage Structures
We now move into a series of posts about elements of browser-side storage. As discussed in my second post, there are seven forms of storage that are standard in browsers today :
- Session Storage
- Local Storage
- Indexed DB
- Web SQL Databases (WebSQL and SQLite)
- Origin Private File System
- Application Cache
- BLOB URL
- Cookies
The Privacy Sandbox has added five other storage technologies that we need to understand before even discussing how the three main products/APIs work. These are:
- CHIPS
- Partitioned Storage
- Storage Buckets
- Shared Storage
- Topics API Model Storage
- Private State Tokens
My goal in all content on this site has been only to talk about Privacy Sandbox technologies as much as possible. However, these different sets of technologies - “pre-sandbox” and “post-sandbox” are not unrelated. In fact, the Privacy Sandbox-related technologies often build on the existing technologies and APIs. For example, even though third-party tracking cookies are going away, not all third-party cookies are going away. Companies that use third-party session management services like Akamai or Cloudflare still need to embed these companies’ strictly-necessary and performance cookies to make use of those services. The problem is that these companies could create cross-site user profiles if their cookies were placed in typical cookie storage, which presents a privacy risk. So Google created a new approach to partitioned cookies that would be required for third-party cookies once 3PCD occurs. The standard for this is called Cookies Having Independent Partitioned State or CHIPS.
So, the way I am going to manage this complexity is similar to what I have done in previous posts. I will provide a high-level primer on the underlying required technology and then explain the new Privacy Sandbox storage element.
Table 1, at the end of this post, shows the various types of browser storage, the subdirectories or SQLite files where they are stored, their format, types of encryption or other protection, and how they can be accessed.
Where is Browser Storage
As I have drilled down into this topic, I realize that a huge amount of data is stored locally in Chrome for all sorts of reasons. Chrome has its own data to store for the browser to manage all its functions. This includes elements like your web browsing history, your preferences, your bookmarks, and favicons for various sites, to name just a very few. But then every extension also has its own data to store. Sometimes they use a standard browser storage element like IndexDB. Sometimes they will use SQLite or another mechanism.
We are not going to delve into any of this. For the most part it is not relevant to our discussion of the Privacy Sandbox. But for our purposes it is enough to note that the discussion in the next few posts only covers a small portion of the data that Chrome keeps locally on your hard drive.
The main directories where Chrome 123 (latest stable version) stores the data we care about are:
On Windows: C:\Users\<your user name>\AppData\Local\Google\Chrome\User Data\Default
On Mac: ~/Library/Application Support/Google/Chrome
Figure 1 is an edited tree view of the \Default directory. Many subdirectories and files that are in \default have been edited out in order to fit the image reasonably on the page. The highlighted items in yellow correspond to the directory elements listed in Table 1.
Figure 1 - Shortened Directory Tree of \Default Chrome Data Storage Directory

One thing that has been most surprising to me is how easy it is to access many of these forms of storage from my desktop, outside Chrome Developer Tools or the browser using code and browser extensions dedicated to that purpose. Using Chrome Developer Tools, it is easy to see the contents of all the forms of storage when visiting a specific web page. But sometimes I may want to see the items in storage when I am not on a specific web page and for that I need some special tool. For example, I was able to see all my keyword search terms from the SQLite database (the history file) by using a SQLite viewer extension (Figure 2). Now these keywords are not only what I have typed in. They are obviously related to the pages I have visited. I did not type in “prebid.js architecture” four times in a row. But I did go to four pages on the prebid website after using that keyword to get there. Also, although I don’t show it, I can see that the file contains 239,000 URLs I have visited (whoa!) and 23,071 links that I have clicked on to go to another page somewhere on the web (whether on the same site or another site) - the kind of metadata that a simple query can provide about a specific table but which Chrome Developer Tools cannot.
Figure 2 - Using a SQL Tool to See the Keywords I have Searched On

Also notice that I have included the location of some of the new storage elements that are part of the Google Privacy Sandbox - in particular, interest groups, private aggregation data (which is part of the Private Aggregation API that will be discussed later), and Shared Storage. We will discuss these storage locations in detail as we discuss the various types of storage and again when we drill into the core products of the Privacy Sandbox.
How Much Storage Can I Use
As we have discussed, browser storage sits on the user's hard drive. So there must be limits to what a browser can store locally. Otherwise, the browser and all its associated applications could, in theory, use up all available storage and leave no room for the user's other applications/data. Alternately, a web site/application could take up so much storage in browser-specific storage as to 'crowd out' other websites/applications. Thus the browser vendors have agreed on guidelines for how much storage the various storage types in the browser can use, although there is some variation between vendors. They have also agreed on standards for how much overall storage all forms of storage can use.
Since right now we are only dealing with Chrome, I will deal specifically with its restrictions. For overall browser storage:
- Chrome allows the browser to use up to 80% of total disk space.
- Chrome reduces the amount of storage an origin can use in incognito mode to approximately 5% of the total disk space.
- When a user enables "Clear cookies and site data when you close all windows" in Chrome, the storage quota is significantly reduced to a maximum of approximately 300MB.
As for the per web site/application storage limits, this gets a bit trickier. There are not web site/application storage limits, per se. There are storage limits by origin, which are known technically as storage quotas. Meaning that if my.example.com is an application and my my.example.com/secondary_application is a separate application, then both those applications are using the same storage 'bucket' (we will come back to that term in a later post). and their combined storage use is deducted from the quota of their origin. An origin can use up to 60% of the total disk space. Actually, the way it works is that any origin can use up to 75% of the 80% allocated for browser storage. 80% x 75% = 60%. (BTW, if you are really ambitious, don't forget that the Chromium project, on which Chrome is based, is open source code and you can check the limits and the way they work yourself here. But if you are that good at this, you should probably just get on with your coding work and stop reading.)
75% you say. That sounds like a huge amount of available browser storage to give to a single application. Well, it actualy doesn't work that way unless there are no other origins fighting for storage space, which pretty much never happens. Even if you have only one page open, you may still have embedded content - like a iFrame - from another origin that will take up quota for that origin. How exactly it works is well beyond the scope of this blog. But leave it to say that space is dynamically allocated based on the overall available storage on the user's computer, the storage typically used by the origin, the kinds of data being stored by the origin, and how many other origins are demanding storage space and what their typical needs are. This gets very complicated very fast. For example, a file loaded from a hard drive may only be 300 KB, but because it comes from an opaque URL (remember I told you we'd need this definition) the minimum space allocated for it for security reasons is 7MB!
If that isn't complicated enough, consider an application like an addThis or 'like' button that is embedded on the page (can be in an iFrame or not). That embedded element's storage cost is charged against the storage quota of its origin, not the web page it is on. Can you see how trying to predict the use of storage quota suddenly gets complicated if your site is the origin? The developer can't know how many browser tabs with different origins are open in that user's browser that have their app embedded. They also cannot see when their element is loaded, so they can't easily know exactly how much quota their app is using. The only way to handle this is to watch how often their application reaches its storage quota from those embedded elements and make some general estimates. If you are the coder for the application, you need to write an "exception handler" for situations where you hit your storage quota so that the application doesn't crash the site in which your application is embedded. I guarantee you that the maker of that embedded application will soon be out of business if that happened.
Google has provided some relief for developers through their Living Storage specification and StorageManager API. This allows developers to get estimates of the use of their storage quota so that they can both understand how much quota all the aspects of their business online are using and then write exception handlers for when certain estimated storage limits are reached.
After all the long posts I’ve written, we’ll make it easy today and keep the post short.
NEXT UP: Cookie Basics and Cookies Having Independent Partitioned State (CHIPS)
Table 1 - Summary of Browser Storage By Type

Browser Elements: Part 3: Navigators, Promises, and Beacons
Today we dive into the last three elements of the main browser frame before moving into browser storage: navigators, promises and beacons. These elements are not specific to the Privacy Sandbox. Promises are a standard structure in JavaScript; navigators and beacons are core browser elements in HTML5. However, they are used extensively by the Sandbox. As a result, we will need to understand what they are when we explore details of the three main APIs in later posts.
Navigators
What Are Navigators
A navigator is a built-in object of web browsers in the HTML specification that allows the developer to query the state of various elements of the browser itself, the user's environment, and the current webpage.
Navigators are supported by all major browsers and have been part of HTML since an update to HTML 3.2 in 1999. They are deeply ingrained in HTML and have evolved substantially over the years. You will find that navigators are ubiquitous in JavaScript approaches to client-side functionality.
Navigators provide a restricted set of information about the user and their environment. They focus on non-personally identifiable details (like browser name, language) or require user permission for potentially sensitive data (like location). In that sense, they are considered privacy-preserving. However despite their intent, some navigator properties (like user agent combined with screen size, etc.) can be used for "fingerprinting." By combining seemingly innocuous details, a website might be able to uniquely identify a user across different websites, raising privacy concerns. Which means their use could violate a core design principle of the Privacy Sandbox.
Modern browsers and coding practices often sandbox functionalities within navigators, preventing them from accessing more sensitive information about the user's device or browsing history. This is how the Privacy Sandbox employs them, thus reducing the potential for fingerprinting.
The reason navigators are so important to the Privacy Sandbox is due to the amount of data stored in the browser and referenced via the user agent header. Interest group functionality is the most visible example of this. During an auction, finding interest groups that can bid in the auction involves a call to the user agent header to access that information. Without navigators, accessing this data would be much more difficult and, I would expect, have higher processing overhead in a situation where scaling Sandbox functionality requires code that minimizes processing time.
Thus the Privacy Sandbox is making a tradeoff between, on the one hand, coding efficiency as well as control over the user's environment and, on the other hand, protecting user privacy.
Let me give a few examples of generic code that is easy to understand even if you aren’t a coder and then let me provide an example of how the Privacy Sandbox uses navigators.
Generic Use Case 1
The first simple example is where a web application uses the navigator.userAgent property to identify the user's browser type (e.g., Chrome, Firefox) for basic compatibility checks.
if (navigator.userAgent.indexOf("Chrome") !== -1) {
console.log("This user is likely using Chrome.");
}
You can see the structure: navigator + userAgent + indexOf:
- navigator tells the browser it wants to access browser status
- userAgent is the read-only property that returns the user agent string for the current browser
- indexOf() is a function that returns the value of the item queried for in the string that has been returned.
Generic Use Case 2
Web applications can use the navigator.geolocation endpoint to request the user's location with their permission. This can be helpful for features like weather apps or location-based services.
navigator.geolocation.getCurrentPosition(
(position) => {
console.log("Latitude:", position.coords.latitude);
console.log("Longitude:", position.coords.longitude);
},
(error) => {
console.error("Error getting geolocation:", error.message);
}
);
I think the code is pretty self-explanatory.
Interest Group Functions in the Privacy Sandbox
This is our first real, if small, foray into the details of Privacy Sandbox - so welcome to the Sandbox! We will revisit the topics covered here in greater detail in later posts about interest groups. For now I’ll do my best to give a short but useful explanation of what you are seeing.
As mentioned previously, one of the major design principles of the Privacy Sandbox is to keep all data in the user’s browser. A core piece of data are interest groups. In the most simple description, interest groups represent the audiences that a browser “fits’ into based either on:
- an advertiser or publisher “telling” the browser that
- the user being automatically added to an interest group through algorithmic classification based on the user’s behavior in the browser.
For each interest group, the browser stores information about who owns the group, what ads the group might choose to show, various JavaScript functions and metadata used in bidding and rendering, and what servers to contact to update or supplement that information.
The functions around interest groups that draw upon navigators include:
- joinAdInterestGroup()
- leaveAdInterestGroup()
- clearOriginJoinedAdInterestGroups()
- runAdAuction()
Let’s look at joinAdInterestGroup() to get a sense of how the Privacy Sandbox uses navigators.
The structure of the navigator for joinAdInterestGroup is very simple:
const joinPromise = navigator.joinAdInterestGroup(myGroup);
The complexity comes with the parameter for joinAdInterestGroup called identified in this code snippet as myGroup. myGroup is a JSON structure that provides all potential information needed to join an auction. This is not the time to get into that structure. However, the next partial code snippet give you a small sense of what the code to invoke the joinAdInterestGroup() function looks like:
const myGroup = {
'owner': 'https://www.example-dsp.com',
'name': 'womens-running-shoes',
...
(more parameters I have removed to be covered later)
...
'ads': [{renderURL: shoesAd1, sizeGroup: 'group1', ...},
{renderURL: shoesAd2, sizeGroup: 'group2', ...},
{renderURL: shoesAd3, sizeGroup: 'size3', ...}],
...
(more extensive parameters about the ads I have removed to be covered later)
...
};
const joinPromise = navigator.joinAdInterestGroup(myGroup);
You can see pretty easily what is happening. The part of the myGroup structure shown defines:
- the owner of the interest group
- the name of the interest group
- The ads to be associated with the interest group that can potentially be shown when this interest group wins a bid
The navigator then calls the joinAdInterestGroup() function which stores the interest group in partitioned storage both individually and in what is called an interest group set.
Hopefully that gives you a pretty good sense of what a navigator is and a simple idea of how that structure is used in the Privacy Sandbox
Promises
In the prior example, you may have noticed the constant called “joinPromise”. While this is just a constant name in code, the name is relevant because it refers to a JavaScript element called, not surprisingly, a Promise. Promises run asynchronous operations in Javascript. These instructions run in the background until they finish processing, and they do not stop the JavaScript engine from accepting and processing more instructions.
I think it is pretty obvious with multiple bidders bidding on multiple auctions on a single publisher’s page that the Privacy Sandbox would have to run these operations asynchronously to function. Since the result (success or failure of the operation) isn't immediately available, these functions return a promise object. This promise acts as a placeholder, representing the eventual outcome.
Also, you will see references worded like this in the specifications:
“There is a complementary API navigator.leaveAdInterestGroup(myGroup) which looks only at myGroup.name and myGroup.owner. As with join calls, leaveAdInterestGroup() also returns a promise.”
Saying "returns a promise" is a concise way to convey that the function doesn't provide the immediate outcome but sets up a mechanism (the promise) to handle it later. It avoids cluttering the explanation with details about promise resolution or rejection.
You can think of the phrase “returns a promise” as developer shorthand for “The function initiates the asynchronous operation and returns a promise that will eventually indicate success or failure.”
Beacons
Web applications often need to issue requests that report events, state updates, and analytics to one or more servers. They do this through web beacons. A beacon is a tiny, often invisible, image element embedded in a webpage or email that sends a one-way communication to a server . When a user opens the page or email, the beacon makes a request to the server hosting the image, indicating that the content has been accessed and sending back the required data.
Web beacons primarily serve three purposes:
- Tracking User Activity. They can record page views, email opens, clicks on specific elements, and user journeys across a website.
- Campaign Measurement. They help analyze the effectiveness of advertising campaigns by tracking how often ads are displayed and clicked.
- Content Personalization. In some cases, they might be used to personalize content based on user behavior (though privacy concerns limit this use today).
Programmatic advertising servers are constantly collecting data back from browsers in real-time. In the case of the Privacy Sandbox, data is collected in the browser, either at an event or aggregate level, and needs to be sent back to the publisher’s or advertiser’s servers (or their adTech partners) in a near real-time basis. Beacons would be one obvious way to handle this.
However, traditional beacons have limitations around privacy and security that make them inappropriate for use in the Privacy Sandbox. As a result, the Protected Audiences API has defined a new function called registerAdBeacon() which is called in the reporting worklet (read “script runner”) that provides the same functionality as a beacon but in a secure manner. The registerAdBeacon() function is only available in the reporting functions, and is not available in the buyer's bidding logic or the seller's scoring logic.
While registerAdBeacon() shares some functionalities with web beacons, it's not a direct equivalent. The key differences between beacons and registerAdBeacon() include:
- Consent and Privacy. Unlike traditional web beacons, registerAdBeacon() operates within the framework of the Protected Audiences API, which emphasizes user consent and privacy-preserving mechanisms.
- Structured Data. The data reported through registerAdBeacon() is more structured and informative than the basic information a web beacon transmits.
- Security Context. The data that is available to be reported comes from within a fenced frame, meaning it is limited by the privacy restrictions of that environment. When an ad is rendered in a fenced frame, the developer triggers a custom event by calling a specific function window.fence.reportEvent(). Data available within the fenced frame is added as a payload and sent to the reporting worklet. The reporting worklet can then create a beacon and call it in the key reporting functions of the Privacy Sandbox we will discuss in a later post - reportwin() and reportresult(). Here is a simple example of what that code might look like, taken from Google’s documentation:
// Protected Audience API buyer win reporting worklet
function reportWin(auctionSignals) {
const { campaignId } = auctionSignals
registerAdBeacon({
click: `https://buyer-server.example/report/click?campaignId=${campaignId}`
})
}
So there you have it. Three key elements of web browsers that we will need to understand the inner workings of the Privacy Sandbox.

Browser Elements Part 2: Worklets and Script Runners

Introduction to Worklets and Script Runners
This post covers the next unique element in the browser that has been adapted for the Google Privacy Sandbox: worklets. Actually, not worklets per se. A special version of worklets developed specifically for the Google Privacy Sandbox called script runners, which unless you read the HTML version of the Protected Audiences API spec carefully you can completely miss. 99% of the documentation around Protected Audiences API uses the term ‘worklets’ when it actually means ‘script runners’. I have argued with the powers that be that they should convert references to ‘worklets’ in the documentation to ‘script runners’, but have had no luck so far. My guess is developers are more familiar with the worklets concept, so referring to script runners in that fashion makes it easier for developers to understand what is happening, even if it means the business folks get confused. Go figure.
Worklets were introduced in Chrome 61 (2017) specifically for performance-critical tasks related to audio processing, video manipulation, and animation. They:
- allow for multi-threaded execution off the main Javascript thread.
- were designed for tight integration with browser APIs.
- have restricted capabilities to ensure security and minimize attack vectors.
The main driver for their development was the need to handle highly specialized tasks within the browser engine with strong security measures for sensitive operations.
Worklets have been adapted into script runners by the Google Privacy Sandbox for three specific uses:
- Running auctions
- Bidding on auctions
- Reporting on the results of auctions
We deal only superficially with these use cases in this post. It sets the stage for later discussions delving into script runner functionalities in greater detail. What this post should help you understand is why Google chose worklets and script runners as the best technology to implement those use cases.
To discuss script runners, we have to wend our way first through worklets and their unique features. And before that, there are browser elements called web workers from which worklets were themselves derived. So we start the discussion there.
What are Web Workers?
To understand web workers, it is important to go back in time to the early 2000s. Web sites were relatively simple then and ran an amount of JavaScript that could be processed in the main thread without unduly impacting the browser’s rendering speed. Over time, developers started to develop more computationally expensive applications in the browser, for example large image processing. The result was an obvious need for some mechanism allowing these computationally-expensive elements to run in a way that reduced performance impacts on the main Javascript thread to maintain an acceptable rendering speed. The Web Worker API was the solution. It was developed in the W3C Web Hypertext Application Technology Working Group (WHATWG) in 2009 as part of HTML5. Web workers are now part of the main HTML specification.
Web workers perform computationally intensive or long-running tasks in a separate thread, improving responsiveness of the main thread. They were intended to be used for long-running scripts with high startup performance costs and high per-instance memory costs, that are not interrupted by scripts that respond to user-generated interactions. This allows these long-running tasks to execute without yielding computational priority, thus keeping a web page responsive. Workers were always considered to be relatively heavyweight. They are supposed to be used sparingly for any given application.
Figure 1 - A Simple Example of a Web Worker. You define the worker first, then can send or post messages to the worker as it runs in parallel with the main thread

Web workers are general purpose and handle a wide range of functionalities. They access the DOM in a limited way and interact with network resources like fetching data or making AJAX requests. Communication is primarily through a postMessage call in JavaScript. postMessage requires data to be serialized, which limits the size of data that can be transferred without impacting performance. Their DOM access is also only indirect through the postMessage call, which reduces the risk of manipulating the main page content.
Besides limitations on DOM access, web workers have other security restrictions that help reduce certain attack vectors:
- Limited API Access. While they have access to some APIs, they lack access to sensitive APIs like localStorage or geolocation.
- Same-Origin Policy. Web workers are subject to the same-origin policy, meaning they cannot access resources from different origins unless explicitly allowed.
These relatively limited security restrictions are a major reason why web workers are not adequate for use in the Google Privacy Sandbox.
What are Worklets?
As mentioned in a prior post, worklets are a new concept that was part of the CSS Houdini specification and were released in Chrome 61 in 2017. Worklets are a lightweight version of web workers geared to specific use cases. They allow developers to extend the CSS rendering engine to handle custom CSS properties, functions and animations. Worklets are similar to web workers in that some types of worklets, specifically audio and animation worklets, can run scripts independent of the main JavaScript execution environment.
Worklets were specifically designed to provide developers more control of how browsers render pages. It allows them to extend beyond the limitations of CSS. Instead of using declarative rules to render a specific element, worklets allow the developer to write code that produces the actual pixels on the page.
Before delving into worklets, you may be wondering how something designed for managing UI and content elements applies to backend processing functionality like auctions, bidding, and reporting. This is where things get a bit hazy. Nowhere online can I find a discussion of how, when, and why worklets began being used for use cases other than rendering. Yet at some point, developers realized that the enhanced security and isolation provided by worklets, as well as some of their other features, made them the best choice for running processes unrelated to rendering. You might call this an “off-specification use.”
The best guess regarding how worklet use cases evolved comes from the Chromium documentation and Mozilla main documentation pages on worklets. The Chromium page identifies four types of worklets broken into two classes:
- Main thread worklets (Paint Worklets and Layout Worklets): A worklet of this type runs on the main thread.
- Threaded worklets (Audio Worklets and Animation Worklets): A worklet of this type runs on a worker thread.
The Mozilla main documentation page on worklets, on the other hand, has a table (Table 1) that identifies the following types of worklets:
Table 1 - Types of Worklets in Mozilla Worklets Documentation Page
Source: https://developer.mozilla.org/en-US/docs/Web/API/Worklet
Notice the last row of the table - for Shared Storage worklets. These are part of the Shared Storage API, which is one storage type specifically used by the Google Privacy Sandbox. We will deep dive into the Shared Storage API in a later post on the Privacy Sandbox’s storage elements. This is a new API, currently still in draft, that was developed as a complement to storage partitioning, which was described in our last post.
Storage partitioning was designed to reduce the likelihood of cross-site tracking. The problem with partitioned storage is that there exist legitimate AdTech use cases that require some form of shared storage to implement. The Shared Storage API (shown as a storage service in our services architecture diagram in a prior post) is used for two very specific purposes in the Google Privacy Sandbox:
- Reporting data across auctions, advertisers, and publishers in a manner that prevents cross-site leakage. The worklet uses a number of technologies, including adding noise to the data that is pulled from storage, to prevent recombining data across sites that would allow for cross-site leakage.
- Rendering of the winning ad from an auction into a fenced frame using cross-site data in a way that limits the potential for mixing data between two entities. The developer uses JavaScript to select a URL (in this case an opaque URL) pointing to ad creative from a list of available ads that were placed in shared storage during the bidding process. The developer can then use the API to render the ad from the winning bidder into a fenced frame.
The intention of the Shared Storage API is to not partition storage by top-frame site, although elements like iFrames and fenced frames would still be partitioned by origin. How then to prevent cross-site re-identification of users? Basically, the designers require that data located in shared storage can only be read in a restricted environment that has carefully constructed ways in which the data is shared.
Thus was born the notion of shared storage worklets. This is because their fundamental design provides an excellent mechanism to allow shared storage and while minimizing the attack surface for potential cross-site re-identification of users.
Chrome 86 (released in April 2020) introduced shared storage worklets as an experimental feature. They still remain experimental, according to Mozilla. They allow developers to run private operations on cross-site data without the risk of data leakage. This is particularly useful for scenarios like fenced frames where isolation and privacy are crucial. As an experimental API, the Shared Storage API has limited documentation (in the W3C draft Shared Storage API specification and the Shared Storage API explainer in the Github repository), and its availability and functionality might differ across browsers and could change in the future.
The Shared Storage worklet is the first official indication we have that worklets can do more than just improve the performance of audio and CSS rendering. We will study it in greater detail in the post about shared storage. For now, note that extending worklets beyond their original use cases has already been considered and implemented as part of the Privacy Sandbox.
Unique Features of Worklets
Let’s now turn back to the differences between web workers and worklets. There are some core differences between the two elements that make worklets the best platform for background processes in the Privacy Sandbox.
- Worklets have stronger isolation versus a web worker. Web workers run in a separate thread, providing isolation from the main thread and other web workers. This prevents JavaScript code running on the main thread from directly modifying data or interfering with the worker's execution. However, they still have DOM access, can share data through message passing, and potentially leak information through side-channels. Worklets have restricted access to the DOM, significantly reducing the risk of manipulating the main page content or leaking information through DOM elements.
- Worklets have a reduced API surface. Worklets restrict access to a number of APIs. Many of these APIs, available to web workers, have access that could provide opportunities for potential information leakage through side-channels. Table 2 shows the list of restricted APIs and why those restrictions are in place.
Table 2 - API Restrictions in Worklets vs. Web Workers
- Worklets are thread-agnostic. Worklets are not designed to run on a dedicated separate thread, like each worker is. Implementations can run worklets wherever they choose (including on the main thread). This feature allows the Sandbox to utilize worklets within the main thread without compromising isolation. The reduced need for dedicated worker threads simplifies the isolation management within the Sandbox environment.
This is important from a performance perspective. The browser can leverage the main thread's existing resources for less intensive worklets, potentially improving overall responsiveness.
- Worklets are able to have multiple duplicate instances of the global scope created, for the purpose of parallelism. While traditional web workers have a single global scope, worklets allow creating multiple instances with the same global scope. This enables parallelism within a single worklet instance.
In a later post we will discuss that this can be critically important for auctions and bidding. It could, for example, allow a bidder to bid on multiple auctions on a single page without having to create separate worklets and the computational and memory overhead they represent.
- Worklets do not use an event-based API. Instead, classes are registered on the global scope, whose methods are invoked by the user agent. This design choice potentially simplifies the security model for worklets as it reduces the attack surface compared to event-based communication, which involves registering and processing various event listeners.
This feature is important to the Privacy Sandbox because registering and managing numerous event listeners, potentially across different objects, could allow malicious code to register for events it shouldn't, or poorly designed code to handle them incorrectly, providing a potential side-channel for information leakage.
A class-based API, on the other hand, has a well-defined set of methods exposed to the user agent. This reduces the attack surface, as attackers have fewer entry points to exploit vulnerabilities. In the context of the Google Privacy Sandbox, Sandbox implementations might define specific classes and methods around use cases that would be allowed within the worklet versus other use cases that would not be. This enables fine-grained control over the functionalities available to the worklet, further restricting unauthorized code execution and enhancing security.
- Worklets have a lifetime for their global object which are specified by the browser vendor. Web worker global objects are typically tied to the worker's lifetime. They explicitly terminate when the worker terminates. Unlike web workers with a more explicit termination model, worklet global object lifetime is defined by the implementation, not the developer. This means the browser vendor determines how long the worklet and its associated data persist.
This implementation-defined nature can be leveraged by the Privacy Sandbox in specific ways:
- Controlled Persistence. The Privacy Sandbox might define specific policies for worklet lifetimes within its environment. This could involve:some text
- Short-lived worklets. For tasks involving more sensitive or temporary data, the worklet and its global object might be terminated shortly after the task completion. For example, reporting worklets currently have a fixed 50ms time limit for gathering information. There has actually been a request from some of the FOT #1 participants to not only make this fixed time longer, but to provide a range so that different ad servers with different (more time consuming) performance characteristics on the code called by the reporting worklet can complete their task.
- Delegating Time Limits for Specific Use Cases. Worklets can delegate worklet lifetime to the developer for specific use cases. This capability is used by the Privacy Sandbox for its auction and bidding services, as auctions and bids have specific timeouts that often differ situationally.
- Enforced Termination. The Sandbox can enforce stricter termination policies, ensuring worklets and their associated data are not retained for longer than necessary, mitigating potential privacy risks.
- Worklets behave differently from workers when changes occur in browser context. Both workers and worklets, as a rule, have a scope limited to a single browser tab. If you change tabs, as you might when checking email while reading an article from a publisher site, then the worker and worklets both can go into background mode and are usually paused.
However, when the focus returns to the original browser tab, the worker will typically automatically resume the communication between the main script and the web worker where it left off, depending on its implementation. Worklets, on the other hand can, and often must, re-initialize or refresh their state when the focus returns to the original tab, especially if they rely on elements or data specific to that tab. For a publisher wishing to start a new auction when the browser focus returns to their page, worklets provide a better vehicle than workers.
Script Runners are “Worklet Like” But are Not Worklets
Script runners, as their name implies, are a script execution environment. Superficially they are similar to worklets in that they run scripts independent of the main execution thread with a flexible implementation model.
However, script runners differ in significant ways that make them “worklet-like” but not actually worklets. These differences are at a fine-grained technical level. I will do my best to keep the discussion “high level”, but there is only so much I can do to up-level the discussion and still make the differences understandable. In all these cases, I will try to provide examples that will make the technical concepts clearer.
- Script Runners are scoped to a user agent as they are spun up by an interest group. Worklets are scoped to a single document. The Protected Audiences API involves user-agent-level decisions about data access based on interest groups. Script runners, scoped to the user agent, can access information across documents within an interest group for better decision-making. This wouldn't be possible with document-scoped worklets.
Here’s an example. You are browsing a news website which wants to access your location data to display personalized news stories. However, it turns out you're part of a "Privacy Focused" interest group that restricts location sharing. That information doesn’t run across a single page. It must be enforced across the publisher’s entire website. Worklets can’t handle this because they are document-specific, and are not scoped to go across an entire website. Script runners, with their scope at the user agent level, can.
- Script Runners have a more flexible agent cluster allocation model. An agent cluster refers to a group of processes within the browser that work together to execute specific tasks. These processes are often isolated from each other for security and performance reasons. Each agent cluster is like its own walled garden. Scripts and data running in one cluster typically cannot directly access or influence scripts and data in another cluster. This isolation helps prevent malicious code from interfering with other parts of the browser or websites a user visits.
The agent cluster allocation model defines how scripts and web content are assigned to specific agent clusters for execution. By default, scripts and content from the same website typically run in the same agent cluster. This ensures some level of coherence for website functionality.
In worklets, the website code and a script share the same execution environment, potentially allowing the website to glean information about the script’s access to data. This presents a privacy risk where data about an interest group can be leaked to the browser.
Protected Audiences utilizes script runners because they have a more flexible allocation model. The script runner executes in a different agent cluster than the HTML document. This creates a physical separation between website code and the scripts contained in the script runner. The website cannot directly observe the script runner's actions, making it harder to infer information about your interest groups or data access decisions.
- Script Runners, unlike worklets, limit WebIDL interfaces. Web Interface Definition Language (WebIDL) is a core browser technology that allows coders to define how various scripts and functions can interact. The Protected Audiences API specifies a set of WebIDL interfaces available to script runners. Any other WebIDL interfaces are restricted.
- Script runners have restrictions on ECMAScript APIs. ECMAScript is a specification that provides standards for writing scripting languages that run in browsers. JavaScript is an ECMAscript-compliant scripting language for example. Worklets have access to a broad set of ECMAScript APIs. Script runners restrict access to only those ECMAScript APIs needed for data access decisions. This limits exposures to both security and privacy risks.
Imagine a script that needs to compare your system’s current date with a specific threshold to determine if location access should be granted based on time-related settings in an interest group. With the ECMAScript limitation in a script runner, the script wouldn't have direct access to the Date object for date manipulation. Instead, the Protected Audiences API might provide a specific function for this purpose within its allowed set of APIs, ensuring controlled access to time-related data.
- Script runners are not module scripts, and are evaluated as if they were classic scripts. Javascript was, and still is in some cases, written in-line in the browser, with code being run sequentially. Historically, this was a limitation compared to most imperative languages. ECMAScript 6 introduced the concept of modules to JavaScript. This made it easier to code and made the resulting code more efficient at runtime in exchange for allowing more complex interactions within the scripts. By opting for classic scripts, Protected Audiences script runners maintain a simpler, more controlled execution model that is well-suited for their core task of making secure data access decisions based on interest groups.
- Script runners have other limits versus traditional HTML to improve isolation. Without going into a great deal of detail, script runners do not allow don’t have access to certain standard HTML functionality in order to provide further isolation and better performance. These include a lack of event runners, no access to settings objects, and no microtask checkpoints
So as you can see, script runners look a lot like worklets, but have a substantial number of key differences at a deep technical level.
According to the leaders of the Protected Audience API working group, there is currently no plan to have script runners turned into a new “standard” worklet concept in the HTML specification. So we are on our own when it comes to deciding how much we want to consider them as worklets versus a new species of HTML element.
Upleveling: Why Script Runners and Not Other Elements
What makes script runners the vehicle of choice for auction and bidding functionality versus workers or “pure” worklets? There a three main areas of concern for the Privacy Sandbox for which script runners provide an excellent platform:
- Performance
- Security
- Data Isolation
We’ll examine each of these in order
Consistent Performance
As any person familiar with real-time bidding is aware, there can be multiple auctions on a page with multiple bidders for each auction. The Google Privacy Sandbox moves the ad server into the browser. As a result, we now potentially have significant performance issues since browsers were never designed to handle this kind of real-time processing, and definitely not at scale with tens of bidders or more for each auction. Because they are based on worklets, script runners are able to run multiple activities in parallel, with script runners being created and closing on different timelines, without impacting the main Javascript thread. Each auction would have its own script runner, as would each bidder whose interest groups qualify for the auction. Web workers were never designed to handle this type of dynamic workload. Moreover script runners like worklets, as previously mentioned, allow for the creation of multiple instances with the same global scope. This enables parallelism within a single script runner instance. This is critically important for auctions and bidding as it could, for example, allow a bidder to bid on multiple auctions on a single page without having to create separate script runners with the computational and memory overhead they represent.
Much of the work in the early TurtleDove experiments and now FOT #1 are centered on optimizing performance of the auction and bidding script runners. There is still a very large question mark around how well script runners will scale once we move beyond the 1% of Chrome traffic being tested (proposed for Q3 2024). It is one of the reasons so much urgent work and testing is happening around server-side auction and bidding functionality in a Trusted Execution Environment. Over time I do not doubt we will see innovation that pushes more of the browser side functionality to the server side without impacting the privacy standards the Sandbox is being designed to maintain.
Lastly, script runners allow for consistent performance within the browser when multiple script runners need to run the same functionality. An example of this was discussed in a particular issue in the FLEDGE Github repository. Certain functions, like private aggregation functions, were initially able to run in the main Javascript thread (top-level script context) of a script runner. But in cases where this top-level script ran once across all available script runners for different players in the auction, the effects of the top-level call to the functions in subsequent script runners was undefined and inconsistent. Moving these functions into the script runner provided both better performance and consistency of execution.
Security
One important item not mentioned above about script runners has to do with something called attestation. Candidate organizations and their developers who wish to employ the Google Privacy Sandbox must formally enroll in the Sandbox platform to be allowed to participate. There is an offline enrollment process with an enrollment form that must be submitted and reviewed by Google. Additionally, there is a second process, called attestation, which is used to confirm that a participant in the Privacy Sandbox has agreed to use specific APIs according to the rules established by Google.
Here is a English version of the core privacy attestation from the attestation GitHub repository:
The attesting entity states that it will not use the Privacy Sandbox APIs or services for the purpose of learning that you are the same user across different sites or apps, and that it will not otherwise circumvent the privacy protections of the Privacy Sandbox.
Developers who submit an enrollment form are then sent a file that contains the attestations for the APIs they requested to use. These are stored in a specific directory on their website (e.g. https://www.example.com/.well-known/privacy-sandbox-attestations.json) and checked regularly by Google to ensure they have not been tampered with. We will discuss attestation at length in a later post, but for now it is enough to know that if the calling site has not included the Protected Audiences API in a Privacy Sandbox enrollment process and made it attestations, the request to add a script runner of this type will be rejected.
The limitations to a single code module, WebIDL and ECMAScript limitations, handling script runners as classic script, among other features, also provides security against sloppy coding or the insertion of additional code modules by evil actors unbeknownst to the owner of the script runner.
Isolation
Isolation of user data between ad tech players to prevent reconstruction of a browser’s identity through cross-site data collection is always at the heart of anything to do with the Privacy Sandbox. Script runners much tighter isolation - no access to the DOM, their reduced API surface, their restricted access to geolocation and browser data, their flexible agent cluster allocation model, their limits on WebIDL interfaces, as examples - provide a better isolation substrate for Privacy Sandbox functionality.
The fact that script runners, like worklets, can have an explicit lifetime is another critical feature for auction and bidding. Publishers or SSPs must put time limits on auctions in order to ensure that ads are returned to all available slots within the browser rendering window.
Conclusion
That was a fairly long discussion, but I hope that after wading through it you now have an understanding as to why this incredibly important new browser element is fundamental to the design of the Google Privacy Sandbox. We will be revisiting script runners again and again as we talk about how the various product-level APIs are implemented. So stay tuned.

Browser Elements Part 1: Fenced Frames
The Discussion So Far
In the prior two posts we introduced two views of the Google Privacy Sandbox. The first was a view to the specific HTML elements that were created or used to implement the Privacy Sandbox (Figure 1).
Figure 1- The Browser with Updates for Google Privacy Sandbox

The second view began a discussion of the APIs, which I consider the true “products” of the Privacy Sandbox, along with a set of shared/supporting services that leverage the HTML elements to deliver auctions, bids, and reporting in the browser (Figure 2).
Figure 2 -Services View of the Google Privacy Sandbox

In the next series of posts, we will tie these together at a high level. This will show how the browser structures and the APIs work together to deliver each piece of Sandbox functionality. I am going to cover these in terms of which structures the APIs impact as follows:
- The main browser frame elements
- Browser storage elements
- Browser header elements
- Early discussion about permissioning
Design Principles of the Google Privacy Sandbox
At the outset of our exploration, I think it is worth restating some core design principles of the Google Privacy Sandbox that we will come back to again and again in future posts:
- Remove cookies and other forms of cross-site tracking at an individual browser level. Current privacy thinking and regulatory frameworks focus on protecting user privacy by:
- preventing the use of tools, like cookies, that can be tied together to create an identify graph where users can be tracked site-to-site.
- preventing aggregation of behavioral data across multiple web sites for the purposes of targeting or retargeting ads or other content to specific browsers.
- preventing fingerprinting of browsers, independent of cookies, that would allow the identity of an individual browser to be known, tracked, and (re)targeted.
- Keep all personally-identifiable information and user activity local to the browser. As a way of implementing this principle, the Privacy Sandbox assumes that all activity data for the browser/user remains in secure storage in the browser. That is a critical mechanic for ensuring that personally identifiable data cannot be collected in a centralized repository and used to backwards engineer a specific user's identity.
- Prevent reidentification/fingerprinting of an individual browser and its data via the mixing of browser activity data from multiple participants in auctions and bidding from within the browser itself. This is similar to point 1c, but it is more subtle and critical to understand about the design of the Privacy Sandbox. If PII data does not move from the browser, then the attack surface to merge data across actors in ad auctions, bidding, and reporting now becomes the browser itself.
All the deep complexity of the Privacy Sandbox and its supporting services is to ensure that such mixing of data among and between participants in ad auctions cannot occur even if ‘evil actors’ want to do so. There is an HTML concept of secure contexts, and a W3C specification dedicated to it. The Privacy Sandbox specifically creates secure contexts for each participant and their data so that mixing cannot occur. Like any design principle, it is unclear whether the Privacy Sandbox in the long-term can implement its needed functionality and still maintain secure contexts at all times. The fenced frames API, for example, calls out that in early instantiations it may not be possible to completely secure a specific context. But whatever the final specification, it will surely create as small an attack surface as possible for the mixing of data by evil actors.
You will see this design concern woven through many of the issue threads in the Protected Audience API Github repository. If you want an example of the type of sophisticated attack that the Privacy Sandbox is designed to handle, see this issue thread. Don’t sweat the details (unless you are a true privacy wonk and Privacy Sandbox black belt). Just get a sense of how thoughtful the W3C Protected Audiences Working Group is being about minimizing the attack surface in the browser.
One area in particular - reporting - is receiving a great deal of attention because it represents the most likely function that can accidentally recombine data to create the opportunity for cross-site tracking. In reporting, data about every winning bid, and in the future the top losing bids, from all websites where an advertiser's ads are shown is aggregated for measurement and billing purposes for both buyers and sellers. That aggregation across the volume of data collected, which for one SSP runs over 1 trillion transactions a day, potentially creates an opening for sophisticated algorithms to identify individual browser behavior across websites if great care is not taken.
- Be Performant. Here’s another, very important way to look at the design of the Google Sandbox. Because of the three prior design principles, the Privacy Sandbox is basically recreating an ad server in a browser while maintaining strict privacy. This means multiple auctions with potentially hundreds of bids for each auction will be running concurrently. Not only does the Privacy Sandbox need to prevent the mixing of data across these hundreds of potential sources, it must also run the multiple auctions and deliver an ad to the browser in parallel in under ~25 ms. That is an incredibly difficult design parameter to achieve using today’s browser technology as it was never designed to scale to that level of functionality.
Main Browser Frame Elements: Fenced Frames
Having laid out the core design priociples of the Privacy Sandbox, let's turn to the first of the new browser elements most critical to its functions: Fenced Frames. The core design goal of fenced frames is to ensure that a user’s identity/information from the advertiser cannot be correlated or mixed with user information from the publisher’s site when an ad is served. To understand why fenced frames were necessary to the Sandbox, we need to understand the concepts of opaque URLs and storage partitions in a browser. Then we can explore why iFrames are inadequate for preventing the potential correlation of user data across publisher and advertiser.
Implementation Status
Fenced frames are not part of the current FLEDGE Origin Trial 1 (FOT #1). Instead FOT #1 includes temporary support for rendering opaque URLs in iFrames. When fenced frames are available for testing, these opaque URLs will be renderable in fenced frames. At a later date, the ability to render opaque URLs into iFrames will not be allowed.
Browser Storage Partitions
Until recently, browsers have tied specific elements on the page only to the origin from which the resource was loaded. But using origin as the single key for identification potentially enables cross-site tracking. Basically this is how third-party cookies work. But this concept also applies more broadly to browser elements such as an iFrame. In the example in Figure 3, website site1 has an embedded iFrame from myvideo.com that delivers a video into the browser. The same iFrame is embedded in website site2. All myvideo.com has to do to perform cross-site tracking of a user's behavior is capture the activity information from each website. The single-key architecture also allows the embedded site to infer specific states about the user in the top-level site by using side-channel techniques such as Timing Attacks, XS-Leaks, and cross-site state inference attacks (don't worry about how these exactly work, for now. We will cover these in a later chapter).
Figure 3 - Example of How an iFrame Keyed Only to Origin Allows Cross-Site Information Flow

Google is moving to a dual-key model with the evolution of the Google Privacy Sandbox (Figure 4). The key consists of two identifiers: the origin of the element and the top-level domain (TLD) of the website into which it is embedded. The information collected is thus partitioned into separate storage buckets. myvideo.com’s iFrame can see the user activity in each storage partition, but it has no ability to use a single identifier to see across partitions. By this mechanic, partitioned storage prevents cross-site tracking, and reduces the attack surface for side-channel techniques. There are other benefits as well, such as protecting offline data in progressive web apps, but those use cases are outside the scope of this discussion.
A second use case where partitioned storage helps (not shown) is when a publisher has multiple iFrames on their website, which often happens when there are multiple ad units on a page. Before partitioned storage, it would be relatively easy to share information. iFrames inherit cookies and local storage data from the main page by default. This allows websites to track user activity across different sections or embedded experiences within the page, even if they belong to different domains. Moreover, by writing JavaScript code that targets both frames, a publisher or an evil actor can directly access and exchange data between the frames. This can be used for tracking user behavior or injecting unauthorized content.
Figure 4 - Example of How a iFrame Keyed to Origin and TLD Reduces Cross-Site Information Sharing

With iFrames in partitioned storage as in Figure 4, each partition has its own storage, including cookies and local storage. This prevents data from one iFrame from directly accessing data stored by another in a different partition. And while direct communication is still possible through JavaScript, it becomes more challenging as each iFrame operates within its own isolated JavaScript environment.
Limitation of iFrames Beyond Partitioned Storage
So, you might ask, we now have an iFrame with partitioned storage. Why is that not adequate to prevent information leakage that allows us to track user behavior between publishers and/or the adTech companies that insert ads into iFrames on the publisher’s page?
The problem with iFrames is that, separately from storage, they have several communication channels which allow them to communicate with their embedding frame. These include both direct and indirect communication channels. Although I do not want to drill deeply into technical detail, I do feel it is important to call these mechanisms out for those who wish to delve further into the topic. Direct channels include:
- postMessage. This widely used API enables cross-frame messaging, allowing data exchange between the main page and iFrames, even if they have different origins. Malicious scripts can exploit this to leak sensitive information or conduct cross-site tracking.
- window.opener. This property provides access to the opener window's object, potentially leaking information or allowing manipulation of the parent page.
- allow attribute. This attribute, mainly for older browsers, allows specifying domains that can communicate with the iFrame using window.opener. Although less relevant nowadays, it could still be exploited in specific scenarios.
- Shared DOM Properties. In rare cases, specific DOM properties might inadvertently be shared across iFrames, leading to vulnerabilities.
- DOM manipulation. Malicious scripts can manipulate the DOM (Document Object Model) within an iFrame to leak information or influence the behavior of other frames on the page.
- CSP (Content Security Policy) While primarily a security mechanism, a misconfigured CSP can inadvertently block legitimate communication channels, impacting functionality. Improper usage might leak information through unintended consequences.
Indirect channels include:
- URLs. The URL of an iFrame itself can leak information, especially if it contains query parameters or encoded data.
- Size Attributes While primarily used for layout, attributes like width and height can be manipulated by malicious scripts to communicate information subtly. This particular item is a bit problematic because the publisher has to communicate the size attributes of the available ad unit in the bid request.
- Name Attribute. Although rarely used, the name attribute can potentially serve as a communication channel if exploited creatively.
- CSPEE (cross-site execution policy) attribute. This rarely used attribute can potentially be manipulated for cross-site scripting attacks if not implemented carefully.
- resize event. Although primarily used for layout adjustments, the resize event can be exploited to send data encoded in the event parameters, especially in older browsers or with less secure implementations.
- window.parent and window.top. These properties provide access to the parent and top frames respectively, enabling potential information leakage or manipulation of the main page.
- onload and other page lifecycle events: Information might be unintentionally leaked or actions triggered through event listeners attached to various page lifecycle events.
- Document.referrer. This property reveals the URL of the document that referred the user to the current page, which might contain sensitive information depending on the context.
- Shared document.domain. In very rare cases, setting the document.domain property to the same value across iFrames can create unintended communication channels, leading to vulnerabilities.
While evil actors who are not the publisher could use these vulnerabilities to perform cross-site tracking across embedded iFrames on a single page, the more obvious vulnerability is that the publisher could, accidentally or intentionally, use these communication channels to collect data across all the iFrames on their page and compile a cross-site view of a browser across multiple advertisers. Partitioned storage alone cannot address those vulnerabilities that can occur within the top-level frame.
Fenced Frames Reduce the Communication Channel Vulnerability
This is the reason a more secure way of delivering ad content to a publisher page was needed. As a result, Google created fenced frames, which
- Explicitly prevent communication between the embedder and the top-frame site, except for certain information like ad sizes.
- Access storage and the network via partitions so no other frame outside a given fenced frame document can share information.
- May have access to browser-managed limited unpartitioned user data such as a Protected Audiences interest group.
A fenced frame is structured, like many other HTML elements, as a tree. The root fenced frame and any child iframes in its tree are not allowed to use typical communication channels to talk to frames outside the tree or vice-versa. Frames within the tree can communicate with each other just like typical iFrames.
Fenced frames behave similarly to a top-level browsing context, just embedded in another page. It can be thought of as similar to a “tab” since it has minimal communication with the top-level embedding context, is the root of its frame tree, and all the frames within the tree can communicate normally with each other.
On the other hand, fenced frames share certain properties with iFrames. Browser extensions can still access a fenced frame as an iFrame. In the case of advertising, this means an ad blocker would still function against a fenced frame the way it does on an iFrame. Developer tools, accessibility features, JavaScript functionalities like DOM manipulation, event handling, asynchronous operations, and the ability to limit third-party API access work similarly in both.
Opaque URLs as Another Means of Reducing Information Exchange in Fenced Frames
As noted above, one of the potential indirect channels for information leakage between sites is the URL of the embedded iframe, since unique query parameters or encoded data could provide an attack surface to reconnect the data between two or more iFrames. To deal with this potential issue, Google has taken another precaution to reduce the attack surface by making URLs for iFrame documents opaque. This is used especially during FOT#1 since fenced frames are not required. Opaque URLs provide at least some amount of protection against information leakage from the iFrame itself. Opaque URLs will continue to be used for fenced frames once they are available and required.
Opaque URLs are designed to intentionally hide the underlying resource information, such as the server, path, or specific file name that a URL points to. They are typically constructed using a cryptographic hash function that transforms the original URL into a seemingly random string.
A regular URL will look something like this:
This URL reveals the server, path, and filename, potentially leaking information about the product being viewed. It’s opaque version would look something like this (using a SHA-256 hash):
This URL shows a seemingly random string generated by hashing the original URL, impeding an attacker's ability to to decipher the underlying resource information.
Equally important, the iFrame doesn't have direct access to the server or resource based on the opaque URL. Instead, it sends the opaque URL to a designated proxy or resolver service. This service, trusted by the browser, holds the mapping between opaque URLs and their corresponding unhashed versions. Thus, isolation between the iFrame or fenced frame and the top-level frame is enforced quite strictly and the potential for information leakage from various attack vectors is substantially reduced.
Fenced Frames Are Not a Perfect Solution
As noted, earlier, the Privacy Sandbox may not be able to completely prevent the mixing of consumer data between advertisers and publishers, or to prevent exploits by evil actors. I’ll end this post with a quote from the Fenced Frames Explainer that states the case well:
Fenced frames disable explicit communication channels, but it is still possible to use covert channels to share data between the embedder and embeddee, e.g. global socket pool limit (as mentioned in the xsleaks audit), network side channel and intersection observer as described above, etc. Mitigations to some of these are being brainstormed. We also believe that any use of these known covert channels is clearly hostile to users and undermines web platform intent to the point that it will be realistic for browsers to take action against sites that abuse them.

Core Services of the Google Privacy Sandbox
The previous post ended with a high-level diagram of the revised Chrome browser that is adapted for the Google Privacy Sandbox (Figure 1). In this article, we will explore in more detail the core products and services that form the browser side of the Privacy Sandbox. Subsequent articles will highlight each element in Figure 1 and explain how it supports/ties into the products and services that need to be delivered (Figure 2). After that, I will delve deeply into each of the services and how they work, referring to only those API calls that are most critical to understanding. Lastly we will tie the entire current flow of a transaction through these browser elements. That is how the Privacy Sandbox works today - the server side elements are still a long way from implementation. We will therefore focus on those elements and their impact on the overall architecture in later articles.
Figure 1- The Browser with Updates for Google Privacy Sandbox
The Core Sandbox Technical APIS/Product Elements
Now it may seem like I am violating my promise to not drill into APIs, but in order to understand the Privacy Sandbox you first need to understand the core product elements, and these products are packaged as APIs with completely separate functions. Just mentally “remove” the term API as I describe them and you will be able to see them as product names.
There are three core browser-centric products in the overall Google Privacy Sandbox "Suite", with many supporting elements (also defined by APIs).
- Topics
- Protected Audiences
- Attribution Reporting
There are also two core server-side products that make up the complete suite which we will cover later:
- Key Management Server (there are at least two in order to provide Multi-party Computation)
- k-anonymity server
I do not think of the balance of the technologies, such as Fenced Frames or DNS over HTTPS, as “products” per se because they are technologies designed to support the core products, not products in-and-of themselves. Many are evolutions of browser standards that already exist or they are additions to the browser, such as secure Shared Storage, which will be available to more than just the Privacy Sandbox.
Topics API
The Topics delivers targeting for what are typically thought of as contextual audiences without cookies as part of the Privacy Sandbox. Contextual audiences are relatively easy to create. You index all the pages on various websites and categorize them by some kind of audience taxonomy. Then you capture in the browser what page a particular browser visits and serve an ad based on the content of that page.
The Topics API goes a bit further. It looks at all the pages a browser visits and algorithmically determines whether the browser "fits" into one of more audiences in a pre-defined taxonomy. If so, it stores that information in the browser for later targeting during an ad auction. This mechanic is why Google does not consider these as contextual audiences and instead as something more sophisticated. I will refer to this type of audiences going forward as "topical audiences".
For example, the IAB has a ~1,500 element audience taxonomy that can easily be used for topical targeting. Google is using a 471-element taxonomy as part of the Topics API. If you were to ask me why Google is not using the IAB taxonomy to provide consistent contextual targeting across Google, publisher sites, and other third-party adTech platforms, I would hazard that the answer lies in the need to maintain k-anonymity for purposes of complying with privacy requirements. In general, an audience must have at least 50-100 members for it to be considered sufficiently anonymous for targeting purposes. A too fine-grained taxonomy makes it difficult to create a large enough audience to meet the anonymity requirement at a time when you are only testing on 1% of all Internet traffic.
The Topics API evolved from what I consider the first true “product” to emerge from the process that led to today’s Google Privacy Sandbox: Federated Learning of Cohorts, or FLoC. Federated learning is a data science approach that allows PII (or any) data to reside remotely (in this case in the browser) and when needed have it sent to a central server in anonymous fashion to update the weights of an algorithm. The weights are then sent back to the remote locale and the algorithm run against the local data.
Google came up with an approach that used federated learning to create topical audiences. A cohort was a short name shared by a large number (thousands) of people, derived from their users' browsing histories. The browser would update the cohort over time as its user viewed pages on the web. In FLoC, the browser used the local algorithms to develop a cohort based on the sites that an individual visited. However, the weights used by the algorithm for each feature were centrally calculated when the browser's local data was sent in anonymized form to a secure server that "federated" the data to generate new weights. At that point, the new weights would be returned to the browser. Those weights would then be used to algorithmically update the browser's inclusion in a specific audience based on it on-going behavior. The central idea that maintained privacy was that these input features to the algorithm, including the web history, were kept only in the browser and were not uploaded elsewhere. The browser only exposed the generated cohort to publishers and advertisers, not any of the user's browsing data, not the algorithm, and not the feature weights.
The FLoC API was developed in 2019 - 2020 and tested in 2021. Testing ended in July, 2021 for the following reasons and these learnings were incorporated into the current Topics API:
- FLoC ended up not using federated learning. Google and others found that on-device computation was faster and less resource intensive. So by definition the whole approach (and naming, obviously) had to change.
- FLoC did not provide enough protection against cross-site identifying information. Because of this, device fingerprinting was still possible. Two academics from MIT found that more than 95 percent of user devices could be uniquely identified after only four weeks.
- The adTech industry wanted more transparency and control over how the contextual categories were created. In FLoC, the automatic way in which contextual audiences were created was a result of the algorithm, not a fixed taxonomy. It was also unpredictable, which meant cohorts could be created around sensitive topics and the adTech providers would be unable to prevent advertisers’ ads from showing in contexts unsuitable for specific brands.
We will drill into more detail on all of these issues when we talk about topical audience creation under the Privacy Sandbox.
Protected Audiences API
The Protected Audiences API is the core product discussed in articles about on-going testing and evolution of the Privacy Sandbox. It started life as something called TurtleDove. To this day I don’t know why bird names were chosen, even though I still have emails in my email folders from Michael Kleber (of Google, one of the core technical leaders of the Privacy Sandbox initiative) about setting up the repository. A series of other bird-named APIs came in - PIGIN, DoveKey, TERN, SPARROW, PARRROT, SPURFOWL, SWAN. Ultimately Turtledove and the best suggestions from these other API proposals were merged into FLEDGE, which stands for First Locally-Executed Decision over Groups Experiment. FLEDGE was then renamed the Protected Audience API (abbreviated as PAAPI or just PA) in April 2023, once the technology looked reasonably viable and a more “product-oriented” name was needed.
The Protected Audience API allows advertisers and publishers to target audiences in the browser based on behavior they had seen - for example, from purchases made on their website - without being able to combine that with other information about the person. That includes who they are, what pages they visit across the web, or what other publishers/advertisers know about them. That capability for publishers and advertisers to capture data from others in the programmatic ad system is called by Google "cross-site (re)identification". It is a term you will see repeatedly in these posts because preventing cross-site reidentification is at the heart of the Google Privacy Sandbox (and actually all privacy-preserving solutions on the market or in design today). PA calls these audiences interest groups but I find that quite confusing, because I tend to think of interest groups being associated with contextual targeting (i.e. people who read certain pages have an interest in that topic). Even the Topics API shows this same issue with defining audiences:
“Interest-based advertising (IBA) is a form of personalized advertising in which an ad is selected for the user based on interests derived from the sites that they’ve visited in the past. This is different from contextual advertising, which is based solely on the interests derived from the current site being viewed (and advertised on).
The term "interests", as in interest groups, is used for audience concepts in both Protected Audiences and Topics APIs. Yet these are very different types of audiences and are stored in different browser storage locations (once again, read “files on the hard drive”).
Moving forward, we will be exact and use "topical audiences" to refer to audiences in the Topics API, and "interest-based audiences" or "interest groups" to refer to audiences in the Protected Audiences API.
The Protected Audiences API is Where Auctions and Bidding Are Handled
The Protected Audiences API is where in-browser auction and bidding functionality are defined, as documented in the main Github privacy sandbox repository. This is why all effort right now is on testing PA: it is where bid requests and bid responses for both topical and interest-based audiences occur. PA also specifies where and how the ad for the winning bid is delivered to the browser and how this operates within the new fenced frames object. So while Protected Audiences API defines how interest-based audiences are created, stored and used, it is the core product of the three because it encompasses all the other services needed to bid for and deliver ads.
Having said this there are concerns, and I think rightfully so, that the computational requirements of running auctions in the browser at scale while maintaining rendering speed may be impractical where devices have limited processing power or there is high network latency. So, as we will discuss at length when we get into server-side discussions, there is server-side bidding and auction services API that is in development to run in Trusted Execution Environments.
The Protected Audience API Also Covers Auction Results Reporting
Reporting on auctions and conversions is a significantly complicated topic in the Privacy Sandbox, and is not yet fully fleshed out. Reporting on conversions, attributing them to specific ads, and the rules by which fractional attribution is done, is handled by the Attribution Reporting API. But reporting on auctions- what the auction structure was, what the winning bid was and its features, and what happened to losing bids, are all covered by PA.
There are two kinds of reports:
- Event-level reports associated with a particular auction, bid and ad delivery to a specific browser. These are only available to the advertiser and , in limited form, to the publisher that displayed the ad. The advertiser may delegate a subset of event-level reports to their DSP or similar adTech partner in some situations.
- Aggregatable reports that provide rich metadata in aggregate to better support use-cases such as campaign-level performance reporting, segmentation based on topical or interest-based audiences, as well as reports combining second- or third-party data to analyze the performance of demographic, psychographic, or other segmentation schemes.
Today, PA reporting is in its infancy. For FOT #1, reporting functions in the Protected Audiences API can send event-level reports directly to participating advertiser/publisher (or their delegates) servers. There is a longer-term plan for doing both event-level and aggregate-level reporting in a way that prevents an adTech from learning which interest groups a particular browser belongs to. The basis for this long-term approach is currently outlined in a draft proposal called the Private Aggregation API. This API covers numerous potential use cases beyond programmatic bidding. As a result, there is also an extension of that API specifically for the Protected Audiences API that is described in the PA repository here.
Reporting is complicated even further because the Privacy Sandbox is built around fenced frames. which will be discussed in the next article. Fenced frames are a privacy-preserving version of an iFrame. The problem is that the reporting functions in PA, named respectively reportResult() for publishers and reportWin() for advertisers, can see results for topical ad requests under the Topics API, but cannot “see” the results of interest-based ad events that occur withiin the fenced frame because of its privacy protections. Therefore a special mechanic is required to extract information about impressions, interactions, and clicks for interest-based ads out of the fenced frame for reporting purposes. This is handled by the Fenced Frames Ads Reporting API endpoints that are part of the PA specification.
Attribution Reporting API
The Attribution Reporting API provides measurement services for both publishers and advertisers to the Google Privacy Sandbox. As described in its documentation, the Attribution Reporting API enables measurement when an ad click or view leads to a conversion on an advertiser site, such as a sale or a sign-up. The API enables two types of attribution reports:
- Event-level reports associated a particular event on the ad side (a click, view or touch) with coarse conversion data. To preserve user privacy, conversion-side data is coarse, and reports are noised and time-delayed. The number of conversions is also limited.
- Aggregatable reports provide a mechanism for rich metadata to be reported in aggregate, to better support use-cases such as campaign-level performance reporting or conversion values.
The API allows advertisers and ad tech providers to measure conversions from:
- Ad clicks and views.
- Ads in a third-party iframe, such as ads on a publisher site that uses a third-party adTech provider.
- Ads in a first-party context, such as ads on a social network or a search engine results page, or a publisher serving their own ads.
Each browser captures the activity and sends encrypted event reports to an adTech server. The adTech server, whether belonging to the publisher or the advertiser (or their proxies, like an SSP or DSP), cannot see the individual events. The adTech server, located in a Trusted Execution Environment, decrypts and then aggregates the individual browser actions into aggregate, privacy-preserving reports. These are the only reports that the advertiser and publisher can see from this API.
One key difference between the Attribution Reporting API and the standard reporting in the Protected Audiences API is that Attribution Reporting API involves a two-sided event. The first event is the ad being shown and activity around that. The second is a purchase or some other conversion event on the advertiser's site. The ad is considered the “attribution source” or “reporting origin” and has a unique source_id, while the conversion action is considered the “destination”. The two events are tied together by a unique destination ID that is registered to the attribution source at the time it is created.
There are two other important aspects of the Attribution Reporting API that distinguish it from auction-based reporting. First, ads can be given priorities. These priorities will represent how much weight they will be given in a fractional attribution system. Second, there is an attribution window which is the amount of time after the ad is displayed or the campaign ends that a conversion will be counted against that impression/campaign. The default is 30 days, but can be set by the advertiser between 1 - 30 days. As of now, 30 days is the maximum conversion window allowed. My guess is this will be extended at some point, since automobile advertisers tend to use longer attribution windows.
A Services View of the Google Privacy Sandbox
Figure 1 showed the physical elements in the browser that support the Google Privacy Sandbox. However, we can take a different view when thinking about the three core products, which are really in themselves nothing more than services delivered through APIs. This view is helpful because it shows all the other services and APIs on which the three core products depend, many of which have their own W3C standards, W3C working groups, and Github repositories. This view is displayed in Figure 2.
Figure 2 - A Services View of the Google Privacy Sandbox
To reiterate a point made in a prior post, I am not trying to show the entire services architecture of Chrome or any other browser. I am only trying to represent enough of the features and services to explain how the Privacy Sandbox works.
The Microsoft Variant
Before closing out, I do want to mention one evolution of the Google Privacy Sandbox that has occurred recently in the marketplace. Microsoft has announced its own version of the Privacy Sandbox, which I will refer to as the Microsoft Privacy Preserving Advertising platform (MPPA). Not clear they have a name for the overarching system quite yet as far as I can tell. MPPA is intended to be largely compatible with the Privacy Sandbox, but uses a variant with substantive changes to the Protected Audiences API called appropriately the Ad Selection API (Figure 3)
Figure 3 - Microsoft's Version of the Privacy Sandbox Services Architecture

We will discuss the differences in these two architectures in detail when we get into the details of auction and bidding for Privacy Sandbox. But let me give a quick summary of the main differences between how they will operate. I say "how they will" as Microsoft's version is still under development and won't have a first origin trial until late in 2024.
- MPPA, unlike PA, allows multi-domain, multi-party, and multi-device processing in transient, trusted, and opaque environments with differential privacy and k-anonymity output gates. One result of this is that MPPA allows the use of bidding signals owned across domains in opaque processes.
- MPPA is server-side only and avoids running auctions in the browser. Microsoft believes that this reduces scalability and other risks associated with a new browser-based model. It also maintains operational design and control with the adTech providers who have the experience and knowledge of their systems to quickly and effectively add the new capabilities. In my mind, this is one of the most significant differences and, as a product manager who always worries about risk, this is certainly a more appealing approach as a transition to a pure client-side auction model.
- MPPA avoids shared services and failure points across all API users.
- Under MPPA, machine learning can run and feed online/offline models back into the opaque auction in real-time.
- Another big difference, MPPA allows creatives to be selected dynamically in the auction. This has been a significant point of discussion in the FLEDGE weekly meetings. Advertiser-side providers see this as a key feature that is missing from PA.
- MPPA enables critical use cases such as page caps, competitive exclusion, and responsive ads through multi-tag and multi-size support.
That’s all for today. In the next article, I will go return to the core browser elements and tie them to the products/services that have been today's focus.

Wordplay
Before we get started there are some terms which are going to appear over-and-over again which you need to understand enough about to be able to follow the discussion. We are going to cover those here. This is not a post you have to read. I am noting it here as a post so you know it is there for you to reference as needed. This will be a living document, so you can always check back in if you see a new term that I haven’t explained before to see if I define it here. Alternately, please use the comments section below to ask me to define terms here that you would find useful.
Navigable (formal definition)
A navigable presents a document to the user via its active session history entry.
Traversable Navigable (formal definition)
A traversable navigable is a navigable that also controls which session history entry should be the current session history entry and active session history entry for itself and its descendant navigables
Origin
An origin is defined by a scheme (such as HTTPS), a hostname, and a port. For example, https://example.com and https://example.com/app/index.html belong to the same origin because they have the same scheme (https), hostname (example.com), and default port. This can also be referred to as a “scheme/host/port tuple”.
The table in Figure 1 below was taken from the Mozilla Documentation on same-origin policy (we’ll get to that in a moment). It provides examples of what is or is not the “same origin).
Figure 1 - Examples of URLs and Whether They Represent the Same Origin
Origins are the fundamental unit of the web's security model. Two elements in a web platform that share an origin are assumed to trust each other and to have the same authority. Elements with differing origins are by default assumed to be potentially hostile actors, and are isolated from each other to varying degrees. The Privacy Sandbox is particularly concerns about cross-origin data being used to re-identify a specific user agent through techniques like browser fingerprinting.
Opaque Origin
An opaque origin is a fairly technical concept for a blog dedicated to semi-technical ad tech readers. But it is something you are going to have to know when we get into cross-origin site access. Browsers usually treat the origin of files loaded from a folder on the hard drive (using a file:/// schema) as being from a different origin from the website that makes the call. These secondary calls are called opaque origins because they contain a “null” instead of a specific URL when a call is made to them.
Partition
A partition is a way to isolate resources, data, or functionalities within a larger system like a web browser.
postmessage()
postmessage() is a Javascript function that sends data locally between the Window objects and does not generate an HTTP request to send data. It allows cross-origin communication between different window objects on a web page. postmessage() will become very important as we get into the internals of the Privacy Sandbox.
Top-Level Domain (TLD)
The highest level in the hierarchical domain name system (DNS) of the internet. Examples include ".com", ".org", ".net", and country-specific codes like ".uk" or ".jp". In a URL, the top-level domain is the root of the of the URL (e.g. www.example.com).
Web Page
A document which can be displayed in a web browser such as Arc, Brave, Firefox, Google Chrome, Opera, Microsoft Edge, or Apple Safari. These are also often called just "pages."
(Web)Site
A collection of web pages which are grouped together and usually connected together in various ways. Often called a "website" or a "site."
(Web) Server
A computer that hosts a website on the Internet.
User Agent
So this definition gets a bit muddy when we distinguish between its formal and informal use. The formal definition of a user agent is a computer program representing a person, for example, a browser in a Web context. You will often see it used as a broad term in specifications, Github repository documentation, and in issues/related conversations to represent not just a browser, but a mobile device, a mobile app, or any user-based device that runs HTML - perhaps an HTML-based app in a CTV environment or a car dashboard.
Besides a browser, a user agent could be a bot that scrapes webpages, a download manager, or another app accessing the Web. But you don’t often see it used that way in general.
User Agent Header
A user agent request header (or in common parlance, the user agent header) is a string that allows servers and network peers to recognize the application, operating system, vendor, and/or version of the requesting user agent. This is important so that the server returns code that will be correctly formatted for the specific hardware/operating system/browser combination making the request The common format is this:
User-Agent: Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions>
And a real-world example is this:
Mozilla/5.0 (platform; rv:geckoversion) Gecko/geckotrail Firefox/firefoxversion
It is well-nigh impossible to figure out just by looking at an uninterpreted user-agent header which specific combination of browser, operating system, vendor, and version is represented. Thus there are services like what is my browser which will convert the gobbledygook above to something a real human can comprehend. Figure 2 shows the conversion of my browser string:
Figure 2: Example of a Converted User Agent Header


Google Privacy Sandbox: The Big Picture & Core Browser Elements
Welcome back! This article will cover two topics
- An overview of the “big pieces” of the Google Privacy Sandbox.
- A first drill down into the browser-based elements/structures that are core to the sandbox.
We are not going to get into flows or “connective tissue” for how the various pieces talk to each other (e.g. OHTTP) for now. We are going to build up the main static elements first, bit-by-painful-bit, exploring all underlying concepts and technologies that reside within and drive the functionality of these “big pieces”. Then we will fit all the pieces together.
Another aspect of my approach that differs from the official documentation is that I am attempting to provide a holistic view across all the APIs. The existing documentation on Google’s site is organized around each API. Makes sense. Each has their own product manager who is responsible for the API and understands its workings. The problem is each of these APIs runs across the different pieces of infrastructure (i.e. servers, browsers) in different ways: sometimes uniquely, sometimes in parallel but without interaction, and at other times with interactions and dependencies on one or more of the other APIs.
The Google Privacy Sandbox is a comprehensive privacy-preserving advertising system that involves topical targeting (which is slightly different than contextual targeting), behavioral targeting, and reporting. It depends for its success on another series of APIs – such as the Private State Tokens API – each of which has its own product owner. Looking at it from the perspective of any single API impedes understanding of how all the parts work to form a functioning whole. Instead we will explore the Sandbox from a systems design perspective. We start with each core piece of hardware/software and identify how the APIs run and interact on that part of the system. Then we build up until the core pieces are connected, which allows us to understand the dynamics of the entire system rather than its piece parts.
An Overview of the Complete Sandbox Architecture and Timeline
So, let’s jump in. Figure 1 shows the core browser elements, server-side applications, and “on-the-wire” improvements to web connectivity of the Google Privacy Sandbox as currently envisioned when it is fully implemented across the Web. This diagram does not represent the technical architecture. It is strictly intended to expose the various components that will be discussed in subsequent articles.
Figure 1- Overview of The Google Privacy Sandbox System
I say “currently envisioned” because we are a long way from a stable release of any component of the architecture. It is possible there will be significant changes over the next one-two years as these technologies evolve. They are:
- The browser (client), with a number of elements, of which several are new (shown in dark grey) that we will cover in more detail in the next few articles.
- An SDK runtime for mobile apps.
- A Trusted Execution Environment (TEE). This is a secure, attested cloud-based environment running Protected Audience API services centrally versus in-browser, usually for performance and scale reasons.
- At least two Key Management Servers run by legally and physically separate entities that provide cryptographic keys needed to support the Sandbox – especially the Key/Value service that is part of the Protected Audiences API. There is a need for two servers because the Protected Audience API uses split private keys as part of multi-party computation to provide better security, as no single party will host any service’s private keys. The companies that run these servers are called Coordinators.
- K-anonymity servers run by Google to provide real-time, algorithmically-derived k-anonymity thresholds to provide protection from microtargeting.
- A publisher’s server(s) where auction logic files are stored and called by the client’s browser to run an ad auction. These server(s) will also contain code for data collection for reporting purposes
- A “buyer’s” ad server(s) where creatives are stored, bidding logic resides that is called from within the browser, and/or source event registration and data collection occur for reporting purposes.
- “On the wire” technologies to better protect browsers from being fingerprinted or data tampered with, including DNS over HTTPS, Network State Partitioning, and IP Protection.
Some of these elements are in testing today in what are called Origin Trials. We described one of these -the FLEDGE Origin Trial - in the last article. Others are in the process of being specified. Others have been specified and have demo or alpha code bases available for testing. This last category is particularly true of the server-based applications needed to complete the platform. Figure 2 shows the history of the development of the core Sandbox APIs, the current plan for deployment to testing and general availability, and an overview of the current status of core technologies for the platform.
Figure 2 - Google Privacy Sandbox API Roadmap


Source: https://privacysandbox.com/open-web/#the-privacy-sandbox-timeline
There are similar roadmaps for the server-side technologies, which will be provided in the articles on each of those applications. In the meantime, they can be found on Google’s Privacy Sandbox site here.
Over the next few posts, I will drill into each core element and examine them in detail. Today we will start a series of posts about the browser and what happens there. There are two reasons for this:
- Replacing the functionality of cookies with a privacy-preserving variant is causing significant changes to the client side of the system.
- The current FLEDGE Origin Trial is focused on understanding the implications of running ad auctions in the browser. Focusing on the browser elements provides a foundation to discuss the current mechanics of the sandbox in the first half of 2024 before the server-side elements come into play.
A Quick Review of Browser Components
Figure 3 shows some core components of a typical client browser before the Google Sandbox. There are three key groupings we need to be concerned about from this diagram:
- The browser header
- The main browser frame, also known as the Body Element
- Browser storage.
Figure 3 - Key Components of Browsers for Google Sandbox Discussion

The "true" technologists will argue that I am skipping a great deal of detail necessary to understand the workings of key components of the Sandbox, such as networking. I agree. But these articles are intended for technically-oriented senior product leaders and AdTech executives who want to understand the Sandbox, so I will only discuss those browser components at a level of detail needed to achieve that goal. For those readers who desire a more complete, holistic view of browsers as a way of understanding the Sandbox, this article by Deepak Puttarangaswamy provides an excellent summary.
HTTP Headers
HTML headers allow the web browser and a server to transfer specific configuration or other details needed to fulfill a request from or response to the browser. When a user clicks to a URL, the browser sends a request that includes a header. This request HTTP header contains additional information for the web server. The web server then responds by sending specific data back to the client to be rendered on the user’s screen. A response header is attached that contains information on whether the initial request went through, type of connection, encoding etc. If the request did not go through, then HTTP response headers will contain an error code.
End-to-End Headers
End-to-end headers apply to both requests and responses, but don’t apply to the content itself. These headers must be present in any HTTP message transmitted to the final recipient. Intermediate proxies must retransmit these headers unmodified and caches must store them. The most common are Connection, Keep-Alive, Cache Control, and Date.
Request Headers
Request headers are important because websites tailor their layouts and design to accord with the type of machine, operating system and application making the request. Otherwise, content might be displayed incorrectly. One important header is the user agent header. It provides critical information on the software and hardware of the source browser as shown in the example in Figure 4.
Figure 4 - Example of HTTP Request Headers (with user agent header highlighted)

We will revisit the user agent header when discussing the User Agent Client Hints API. This is because the user agent header provides a substantial amount of information that can be used to fingerprint a browser and uniquely identify it, thus violating privacy. As part of the Privacy Sandbox, Google has proposed the Client Hints API to enables sites to request the information they need while limiting the information shared about an online user.
Response Headers
A response header is an HTTP header that can be used in an HTTP response and that doesn't relate to the content of the message. Response headers, like Age, Location or Server are used to give a more detailed context of the response.
Representation and Payload Headers
Representation headers contain information about the representation of the resource sent in an HTTP message body. Clients specify the formats that they prefer to be sent during content negotiation (using Accept-* headers), and the representation headers tell the client the format of the selected representation they actually received.
Payload headers describe payload information related to safe transport and reconstruction of the original resource representation, from one or more messages. This includes information like the length of the message payload, which part of the resource is carried in a specific payload (for a multi-part message), any encoding applied for transport, and message integrity checks, among other elements
Each entity tag is represented as a pair. Representation headers include Content-Language, Content Encoding, and Content Location. Payload headers include Content-Length, Content-Range, and Transfer Encoding.
The Main Browser Frame
The main browser frame is where the browser’s rendering engine takes all the HTML, CSS, JavaScript and other information about the web page and displays it in the browser window. Many of the adaptations for the Privacy Sandbox to the client-side architecture occur in the main browser frame. We will not drill into all the sub-elements of the main browser frame here. However, I do want to focus on a few elements/concepts that will be critical to understand which are leveraged/extended to support functionality in the Privacy Sandbox
Web Workers
As the web evolved developers, being developers, wanted to execute “bigger and better ideas” in browsers. Often these web-based applications performed more resource intensive tasks, such as complex calculations for image generation. So, a solution was needed to allow resource-intensive tasks to run in their own threads, in parallel, to ensure browser response times remained tolerable.
The outcome was a specification for web workers. Workers are background threads in JavaScript that execute code independent of the main thread. Introduced in HTML5, they are designed to offload tasks that can be time-consuming or resource-intensive and to overcome the limits of single-threaded JavaScript execution. Workers are relatively heavy-weight, and are not intended to be used in large numbers. They are intended to be long-running scripts that are not expected to respond to clicks or other interactions. Generally, workers have a high start-up performance cost, and a high per-instance memory cost.
Worklets
Worklets are a new concept introduced in the CSSS Houdini specification and, as we will discuss in later articles, are critical to the Privacy Sandbox. Worklets are a lightweight version of web workers that allow developers to extend the CSS rendering engine to handle custom CSS properties, functions and animations. Worklets are similar to web workers in that they can run scripts independent of the main JavaScript execution environment. However, there are some significant differences, Worklets:
- Are thread-agnostic. That is, they are not designed to run on a dedicated separate thread, like each worker is. Implementations can run worklets wherever they choose (including on the main thread).
- Are able to have multiple duplicate instances of the global scope created, for the purpose of parallelism.
- Do not use an event-based API. Instead, classes are registered on the global scope, whose methods are invoked by the user agent.
- Have a reduced API surface on the global scope.
- Have a lifetime for their global object which is defined by other specifications, often in an implementation-defined manner.
These differences, especially those that allow user agents to parallelize work over multiple threads with global scope or to move work between threads as required, as well as the security features that prevent one worklet from accessing user data from another worklet, make worklets - or the Sandbox's variant called a script runner - a perfect vehicle for implementing ad auctions and bid generation in the browser.
iFrames
The term iFrame stands for “inline frame”. iFrames are an HTML element that loads a second HMTL element within the main browser frame of another web page while allowing the user to interact with the content. They are commonly used to embed specific content or other interactive elements into a page. Documents rendered in an iFrame are encapsulated within their own browsing context with separate CSS, JavaScript, and HTML content.
Calling an iFrame requires a single line of HTML:
<iframe src="https://www.example.com/" width="200" height="200" sandbox="allow-downloads"></iframe>No doubt you have heard of iFrames as they are often used to display ads because they provide more flexibility than an inline script. But from the perspective of the Google Sandbox they are problematic because they can provide a browser fingerprinting surface where they can identify an individual based on the ads they have been presented over a period of time. So Google Sandbox had to create a new concept, Fenced Frames, to replace the standard iFrame. We will be talking more about Fenced Frames in the next article.
Navigators
The navigator object provides information about the browser, operating system, and user environment where a web page is running. The Sandbox leverages specific navigators to provide context - e.g. what browser is being used - in a privacy-preserving manner for auctions, bidding, and reporting. For example, the Protected Audiences API uses the navigator.permissions.query({name: 'geolocation'}) method to check if the user has granted geolocation permissions. This can be used as a signal during the auction to determine if the ad displayed should include location-based features. The advertiser receives a simple yes/no answer without any actual geolocation data.
But the Sandbox's use of navigators is much more extensive because Protected Audience interest groups reside in the browser and are therefore a part of its state that a navigator can access. For example, when a user’s interactions with a website indicate that the user may have a particular interest, an advertiser or someone working on behalf of the advertiser (e.g. a demand side platform) can ask the user’s browser to record this interest on-device by making a call to navigator.joinAdInterestGroup() - a new type of navigator. This indicates an intent to display to this user an advertisement relevant to this interest group in some future auction. The user agent records interest group sets, which are a list of interest groups in which owner/name pairs are unique. When an auction occurs, a second navigator for the Protected Audiences API, navigator.runAdAuction(), checks the interest group sets to determine if any of the interest groups from that particular owner qualify for the specific auction.
Navigators are extensively used in the Privacy Sandbox because so much of its functionality runs in the browser. As a result, the API has found a creative way to leverage these existing objects.
Beacons
Beacons are a type of HTTP request that operates asynchronously. This means the browser sends the request and continues executing code without waiting for a response. This is useful for sending data without interrupting the user experience. Unlike other HTTP requests, beacons don't expect a response from the server. This simplifies implementation and reduces network overhead. Beacons are also especially good for small data transfers. The asynchronous nature of beacons and their strength in handling small data transfers make them ideally suited to send anonymized aggregated data about ad impressions, clicks, or conversions in Privacy Sandbox reporting.
Browser Storage
One of the most confusing topics for me even as I worked in AdTech for many years was browser storage. I imagined there was actually some space in the browser itself, similar to HMTL elements in a .html document, where the data used by the browser was stored. Ultimately, I realized that this was not the case. That, in fact, browser storage was nothing more than a set of encrypted files in different subdirectories holding different kinds of data under my c:\users directory (on Windows). These storage elements include:
- Local Storage
- Session Storage
- WebSQL
- Indexed DB
- (Origin Private) File System
- Application Cache
- BLOB URL Storage
- Cookies
The contents of these types of storage can be examined in the Chrome Developer Console (Figure 5).
Figure 5 - Display of Browser Storage Contents in the Chrome Developer Console
One very impotant thing that is unique in this display: note the item highlighted in red at the bottom right. The browser_fingerprint_id is not a standard HTML storage element. It is www.medium.com employing a unique key/value pair for some form of browser fingerprinting. You hear about this as one of the statistical methods for identifying a user when there are no third-party cookies. But you may wonder how it is or where it is done. This is a great, very visible example. I am not logged in, so to Medium I am an anonymous user. This is their fallback when I don't have a first-party cookie or haven't given them my first-party id. And it makes me wonder that if I studied many other sites if I would find an extensive use of similar, blatant tags for browser fingerprinting there.
Local Storage
Local storage holds persistent data that is needed across browser sessions or when a page refreshes for a specific domain. Each domain has its own encrypted file within the storage folder the browser uses on the local hard drive. One domain cannot gain access to data stored in local storage by another domain. Stored data is not automatically sent to the server with every HTTP request. This means that the server will not have access to the data unless it is specifically requested.
Session Storage
Session storage is similar to local storage with one key difference: the data stored in session storage is automatically deleted when the user closes the browser tab or window where the data is stored.
WebSQL
WebSQL allowed websites, extensions or apps to store data in a structured manner on the client. It was based on an embedded database called SQLite. While WebSQL was completely deprecated from Chrome in late 2022, some elements of Chrome still use SQLite. Moreover, to understand the roots of IndexedDB, the Chrome NoSQL database, it is important to know the history of WebSQL, so we will cover it in some depth when we discuss browser storage.
IndexedDB
IndexedDB is a large-scale, NoSQL storage system that allows storage of just about anything in the user's browser. In addition to the usual search, get, and put actions, IndexDB also supports transactions. Each IndexDB database is unique to a site domain or subdomain, meaning it cannot access or be accessed by any other domain. Data storage limits are usually quite large, if they exist at all, but different browsers handle limits and data eviction differently.
Origin Private File System
There are times when applications want or need to be able to write to or read from the local hard drive on which the browser client resides. For example a user may wish to upload local files to a remote server or manipulate local files inside a rich web application. Browsers have a series of API standards that allow developers to build applications that read and write files in a sandboxed subdirectory in the Chrome directory tree (appropriately called File System) You will see the term Origina Private File System in Google documentation because an origin ((e.g. site, an extension, etc.) stores private content to disk that can be easily accessed by the user.
Application Cache
Most people nowadays have enough knowledge of browsers that they understand that the browser's cache is where websites, extensions, and web applications store data about a web page. They know this because as part of security and privacy, they are often asked or directed to "clear their cache". What may not be clear to them is how the cache differs from other forms of web storage. Web cache is specifically designed to hold static web content (e.g. images) to:
- help reduce page load times
- allow web pages that have been previously loaded to display their static content in the event that the browser's Internet connection is temporarily interrupted.
Chrome uses the operating system's disk cache for storing web content. Data is primarily keyed by the URL of the resource being cached. This allows Chrome to efficiently retrieve previously downloaded content for faster page loads. The cache itself is generally not encrypted. This is because the cached data is intended for performance optimization and typically contains publicly accessible web content. The cache uses an expiration mechanism to manage storage space. Older cached files are periodically deleted to make room for new ones. Note that browsing data in incognito mode is not stored in the cache, offering a level of privacy.
BLOB URL Storage
BLOB is an abbreviation for Binary Large Object. Basically they are very large files, can be many megabytes or even gigabytes, that can contain almost any kinds of information. Large file downloads or streaming video are examples of this kind of file. Often the application or user does not want to store these files. They are rendered by the browser and then released from memory. Instead of storing the BLOB, the browser instead stores a pointer to the URL where the content is stored. Then depending on available memory, the application slices the blob data and renders it in pieces. If the BLOB is too large to be held in memory, it can be saved to local disk until momory is available to show the next slice. BLOB storage really isn't storage in the classic sense, which is why it does not show up in the developer tools tree in Figure 5. But I mention it here as it will become important when we talk about how the Sandbox handles partitioned stroage.
Cookies
The quote above is what I first wrote when I published this post. But as I got ready to write about the Privacy Sandbox's storage elements, I realized that how cookies work is actually not obvious. Let me give you some examples of questions that I discovered that you may or may not know the answer to:
- Where are cookies stored in my browser/on the hard drive?
- Are they stored in a file, a set of files, in a database like IndexedDB, or something else?
- How is it that one site cannot "see" another site's cookies?
- If cookies are stored in encrypted form, how are they encrypted and decrypted? What algorithm is used to encrypt/decrypt them?
- Question #3 is important because I have plug-ins in my browser, or I can write code, to show me all the cookies in my browser. So if I can do it or a third-party extension to Chrome can do it, why can't an evil actor web site access information, either directly or by using a browser-based attack to get permissions to my cookie status and history?
If you know the answers to these, then 10 points to Gryffindor and it just goes to show how little I've actually understood our business over the years. But I'm guessing if I don't understand it, most likely neither do many members of my audience.
We won't cover cookies here because, after all, third-party cookies are going away, which is a major driver to create the Privacy Sandbox. But when I get into the Privacy Sandbox browser storage elements, I am going to do a special post on cookies and how they work so you have answers to those questions.
Figure 6 - Summary of Different Types of Browser Storage (needs update)

Source: https://www.geeksforgeeks.org/difference-between-local-storage-session-storage-and-cookies/
Permissioning
Permissions Policy allows the developer to control the browser features available to a page, its iframes, and subresources, by declaring a set of policies for the browser to enforce. With these tools, the top-level site owner can define what it and its third parties intend to use, and removes the burden from an end-user of determining whether the feature access request is legitimate or not. For example, by blocking the geolocation feature for all third parties via Permissions Policy, the developer can be certain that no third party will gain access to the user's geolocation.
Many of the Privacy Sandbox APIs use the browser’s permissions policy to control access to various capabilities. With third-party cookies, the page owner has no granular control over how the cookies are used by third-party iframes. WIth the Privacy Sandbox APIs and Permissions Policy, a page can allow or deny Privacy Sandbox APIs from being used by the page itself and third-parties on the page. For example, a page owner, such as a publisher, can use Permissions Policy to allow specified third-parties to run an ad auction, or deny all third-parties from reading the user's topics.
We will cover permissions policy and how it impacts the Privacy Sandbox in detail in a later article.
The Browser and Google Sandbox
That overview of the browser, while somewhat basic, was important because it provides a baseline of how browsers operated before the Google Privacy Sandbox was conceived. Figure 7 is an updated architectural overview of the Chrome browser with the new Google Sandbox elements. Clearly, a lot of changes are being made to reengineer Chrome, and online advertising as well, to adapt to the new privacy-centric view of the Web. We will delve more deeply into those changes in the next couple of articles.
Figure 7- The Browser with Updates for Google Privacy Sandbox

The Google Privacy Sandbox Explainer: An Introduction
Let me ask you, the reader, a very simple question:
“Do you understand how the Google Privacy Sandbox works?”
By “understand how it works” I mean could you, if asked, create a presentation for managers and investors in your company? Could you describe to your brand’s advertising or privacy groups in moderate detail how it works today? How it currently is envisioned to work when the specification and the underlying systems are completed? Can you do so in enough detail to provide your technically-savvy business teams a sense of the pieces of the platform, the basic “hooks” by which they interoperate, how information flows between advertiser and publisher, and the rationale behind the system's design?
If you can answer yes to that questio n, then stop reading. The information in this series of articles is too basic for you. This can be due to one of two reasons, or both. First, you may be an engineer at one of the 20 companies involved in the FLEDGE Original Trial (FOT) #1, are working with this technology every day and you attend all the regular W3C meetings that relate to the Sandbox (there are at least four taskforce meetings weekly or biweekly). Or second, you are one of the AdTech Ishtári (think Gandalf) who has spent months locked away, empty Red Bull cans strewn at your feet, reading by candlelight through stacks of Github repositories and developer guides on the Privacy Sandbox website trying to comprehend the wide array of technologies underlying this major rewrite of the ad-supported web, along with all their API endpoints and parameters.
I, however, am neither of these, and most likely neither are you. But we both need to understand the Privacy Sandbox and its impact on the products we have to build. And even though we are very technical product people, understanding the Privacy Sandbox, if you aren’t working at one of the FOT #1 firms, is well-nigh impossible. There are several reasons for this:
- Google Sandbox is both a set of technologies and a set of open standards. Much like other open standards, such as Java or Linux, the specifications are being built with, by, and for the community. An open standards process, to use an analogy, is like designing the plane while you are building the plane. But when it comes to Linux or Java, there is usually a stable “production release”, including a reference implementation, that everyone can work from while they work on the next iteration of the specification and reference implementation. In the case of the Privacy Sandbox, the overall design of the core APIs is broadly specified, but the details of implementation of key aspects of the Sandbox are changing weekly as FOT members learn and give feedback. We have not yet achieved a stable V1.0.
- Google Sandbox depends on a wide-range of other browser-centric technologies. Just learning and internalizing these technologies is a tall order. Moreover, like the Sandbox, they have their own working groups and are evolving in parallel.
- Too many groups; too little time. To keep up with current thinking you need to attend all the different W3C working groups (well, at least the core ones) related to the Sandbox. Unless you are directly engaged with FOT #1, it is hard to justify that much time. It is also just plain hard to sit in meeting where you don't have the level of detail needed to engage or give feedback.
- Distributed development across multiple teams. No one group at Google controls all the elements of the Sandbox. For example, the group that is engaged in evolving worklets or the group that defines how subresource bundles work are not in the AdTech group that is responsible for the three core Google Sandbox APIs. It seems to me that there are only a few engineers at Google who can without hesitation stitch a single picture together of all the technical pieces that make up the Sandbox. Coming at it from outside Google – and I have spoken to people in FOT #1 who feel the same as I do - it is almost impossible to piece together that comprehensive view when so many pieces are changing on a weekly basis.
- Still early days. Much of the technology – such as the Trusted Execution Environment, the Key Value Service, and the k-anonymity server - are in early alpha and untested. No one knows exactly how they will work yet (and remember, the devil is in the details). So, while it is possible to describe in broad strokes what the likely architecture of the final Sandbox platform will be, things can still change drastically by the time an actual V1.0 implementation occurs.
- Related proposals evolving weekly. Even more, there are multiple standards proposals in the GitHub repositories from one or more members of the FOT #1 community. They may or may not get implemented – so are they part of the specification or not? They may not be part of the specification, but they are part of the conversation. So it is important to know about them and understand how they could, if implemented, impact the design of the Sandbox.
- Integrations with prebid and OpenRTB remain to be reconciled. The Sandbox has to interact with other open standards like header bidding and OpenRTB from IAB. These interactions are critical to success of use cases like bid optimization and retargeting, yet how these elements will interact with the Google Sandbox can’t be fully defined until there is a stable V1.0 available and in use. So, understanding them is also like trying to keep your aim centered on a moving target.
- Testing in phases to isolate issues and limit risk of delay. Because this is such a complex problem, to minimize risk (and as product manager I completely agree with this approach) Google in FOT #1 is testing only a limited set of in-browser functionality to make sure the “basic engine” works before it adds the more server-side elements. For example, companies in FOT #1 are allowed to use their own ad servers (under the title “Bring Your Own Server” or BYOS) which do not meet the trust requirements of the Trusted Execution Environment required under the long-term design of the specification.
- Loss of "higher-level" perspective comes with deep engagement. Lastly, the Google folks and their FOT #1 partners– like the developers of any software product so complex that you have to live it 24x7 – are so deeply ensconced in the tech that it is hard for them to visualize just how tough it is for tech-savvy business people to grasp how the tech works. They have generated a HUGE amount of content to help educate the industry, and they have done yeoman’s work. But the content tends to be written by engineers for engineers involved in building to the specifications. It has also been developed piece by piece. There is no overarching outline and information flow across every aspect to ‘tell a story’ – like a book might.
So, I’ve decided to begin a series of articles on the Google Privacy Sandbox to provide a “moderately technical” overview of its elements in a “storytelling manner”. This will follow an outline that will stitch together the Sandbox from first-principals and build it up piece-by-piece until the entire structure can be seen and understood as a unified whole . These articles are intended for product managers and other executives in AdTech who wish to understand the Sandbox and its tech at an architectural level, but who don’t want to read the specifications in the GitHub repositories or spend hours on privacysandbox.com going over developer guides. There will be two types of articles:
- Architectural Articles. In each of these I will cover one aspect of the architecture and its design in its current state at the time of writing. You can discover these by selecting a keyword under the Categories tab on the main nva bar or reviewing the table of contents under the Chapters tab and clicking on sections on a specific topic.
- Update Articles. These will provide updates on critical discussions at the various weekly Sandbox-related meetings at the W3C, the IAB, or that show up in the issue threads in Github. I obviously can’t cover all topics and many won’t be worthy of an architectural discussion, but where there are interesting elements to consider I will write about them.
As I end this intro, I want to provide a reference to all the technologies and repositories that impact the Google Sandbox for your use as the series of blog posts expands. There is so much activity related to the Sandbox, either directly or indirectly through more general web technologies, that finding what you need at any given time can be daunting. And then finding the right page in the documentation that talks to specific issues you are interested in on that topic – well, that is often like seeking a needle in a haystack. The List of Specifications under the Resources tab on the main nav bar is intended to be used when you need to look reference something in the specs or across specifications as you continue reading my posts. Any item listed in this table is either part of the Google Privacy Sandbox, one of its related services, one of its historical antecedent versions, or related technologies that are referenced in one of the specifications (and thus you need to understand them).